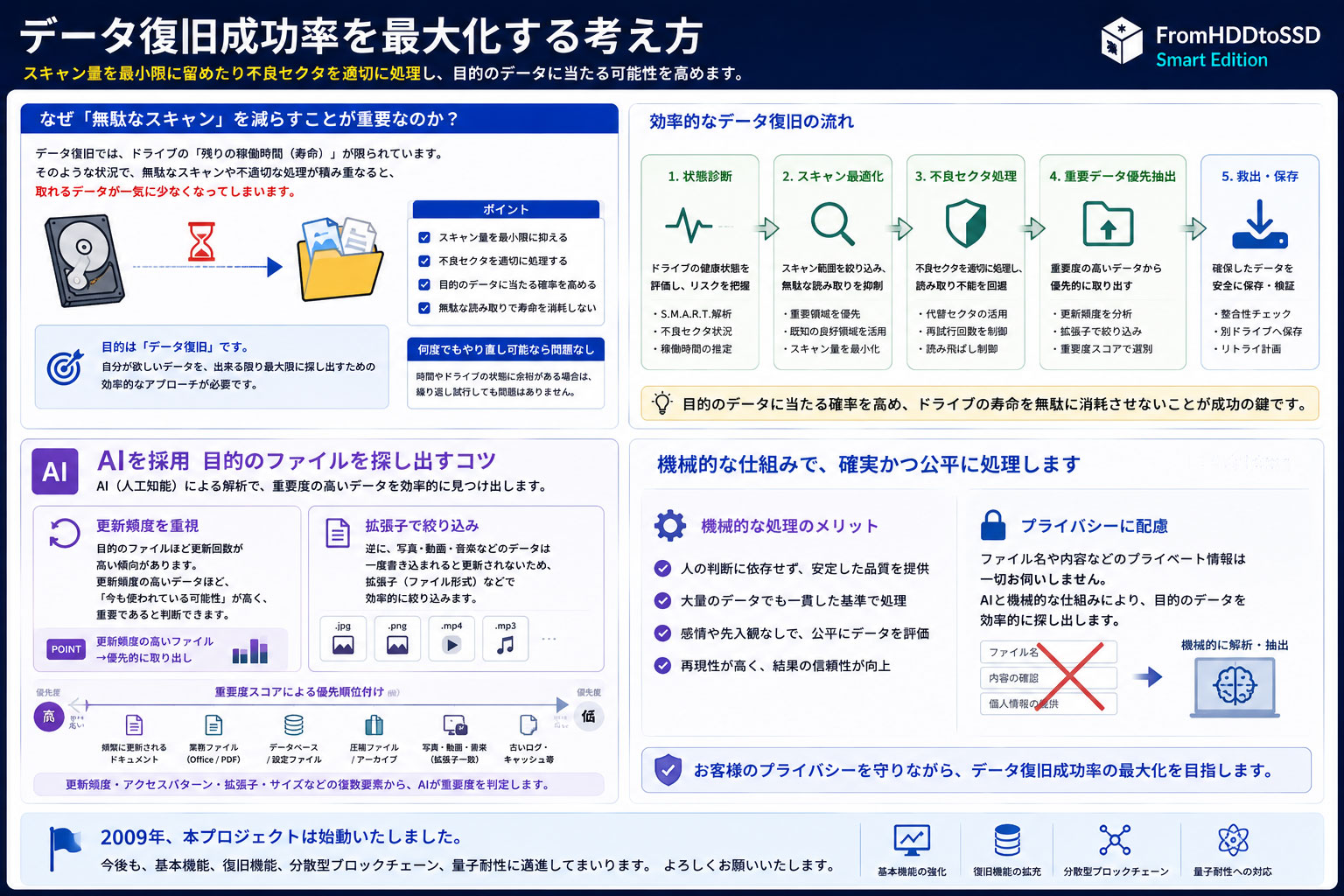
スキャン量を最小限に留めたり不良セクタを適切に処理
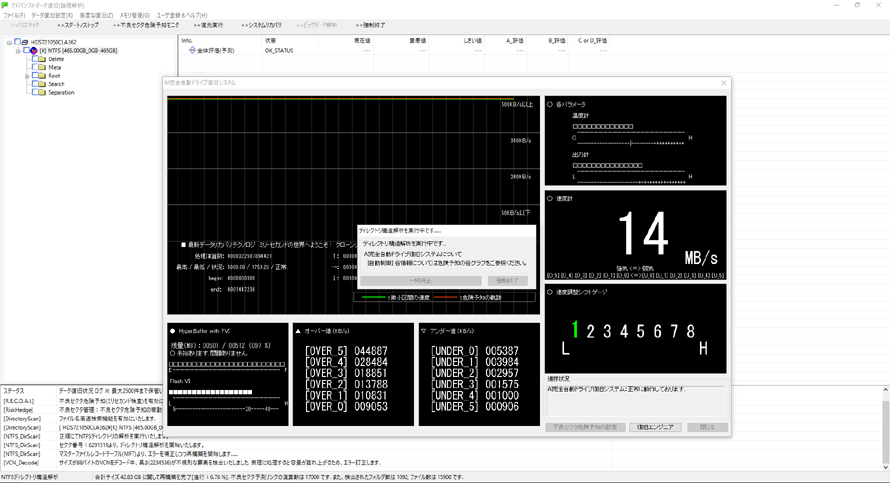
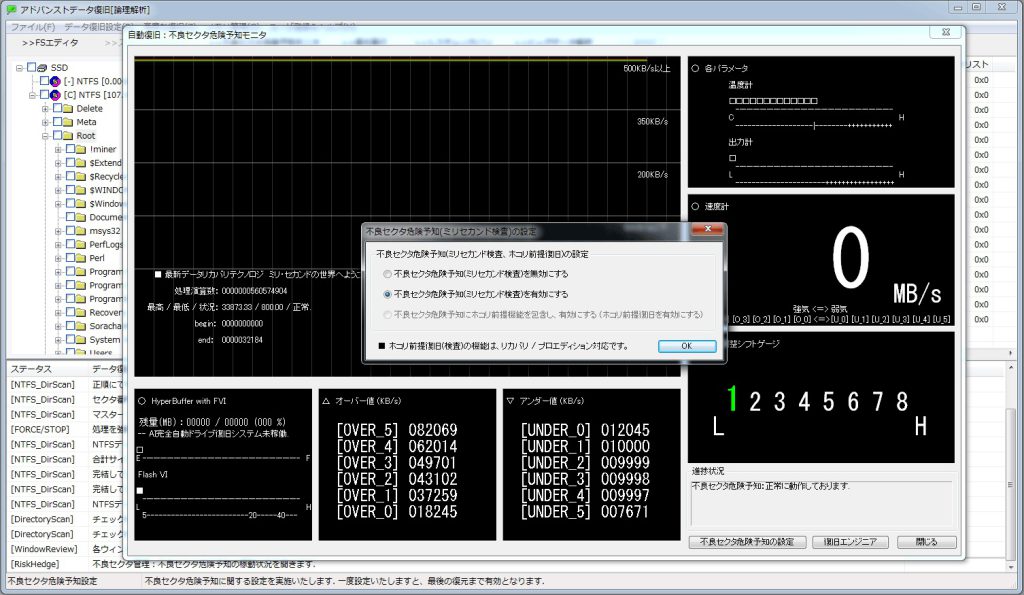
目的のデータに当たる可能性を高めておきますとデータ量が小さいほどデータ復旧が成功に近づきます。何度でもやり直し可能ならばそれでも問題にはなりません。
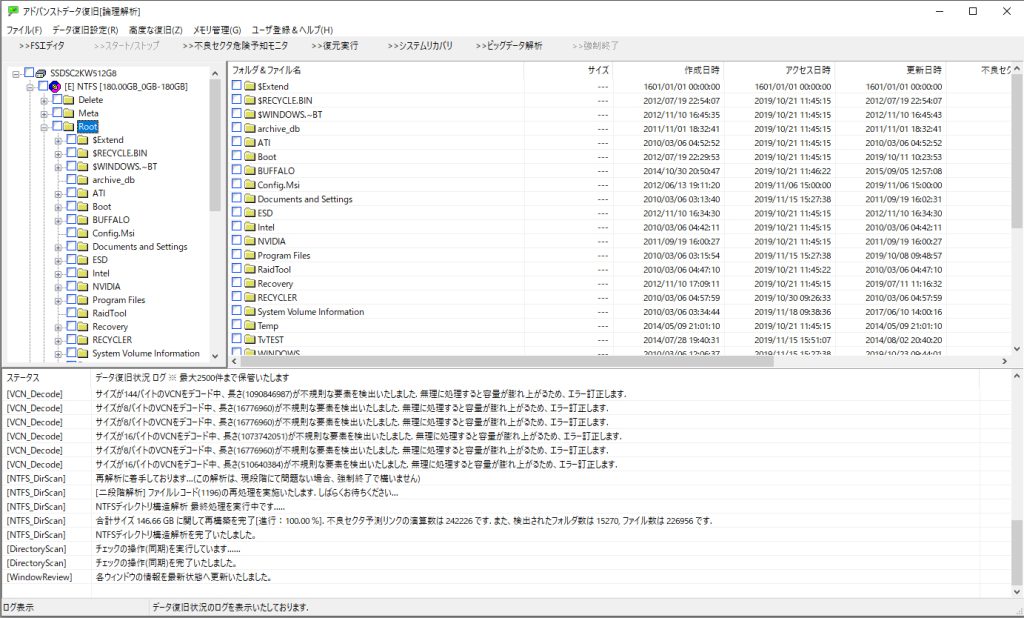
しかし残りの稼働時間が限られるなかそのような無駄が積み重なりますと取れるデータが一気に少なくなってしまいます。目的はデータ復旧ですから自分が欲しいデータを出来る限り最大限に探し出す方法が別途必要となりました
AIを採用 目的のファイルを探し出すコツ
目的のファイルほど更新回数が高い傾向がありますのでそれを利用いたします。逆に、写真等のデータは一度書き込まれると更新されませんのでそのような場合は拡張子などで絞り込みます。
更新頻度等の要素から重要度が高そうなデータを優先的に(機械的に)取り出していきます。データ復旧サービスでもこのような機械的な仕組みで処理いたしております。ファイル名等はプライベート的な問題から伺いません。このあたりは機械的な処理が最適です。