
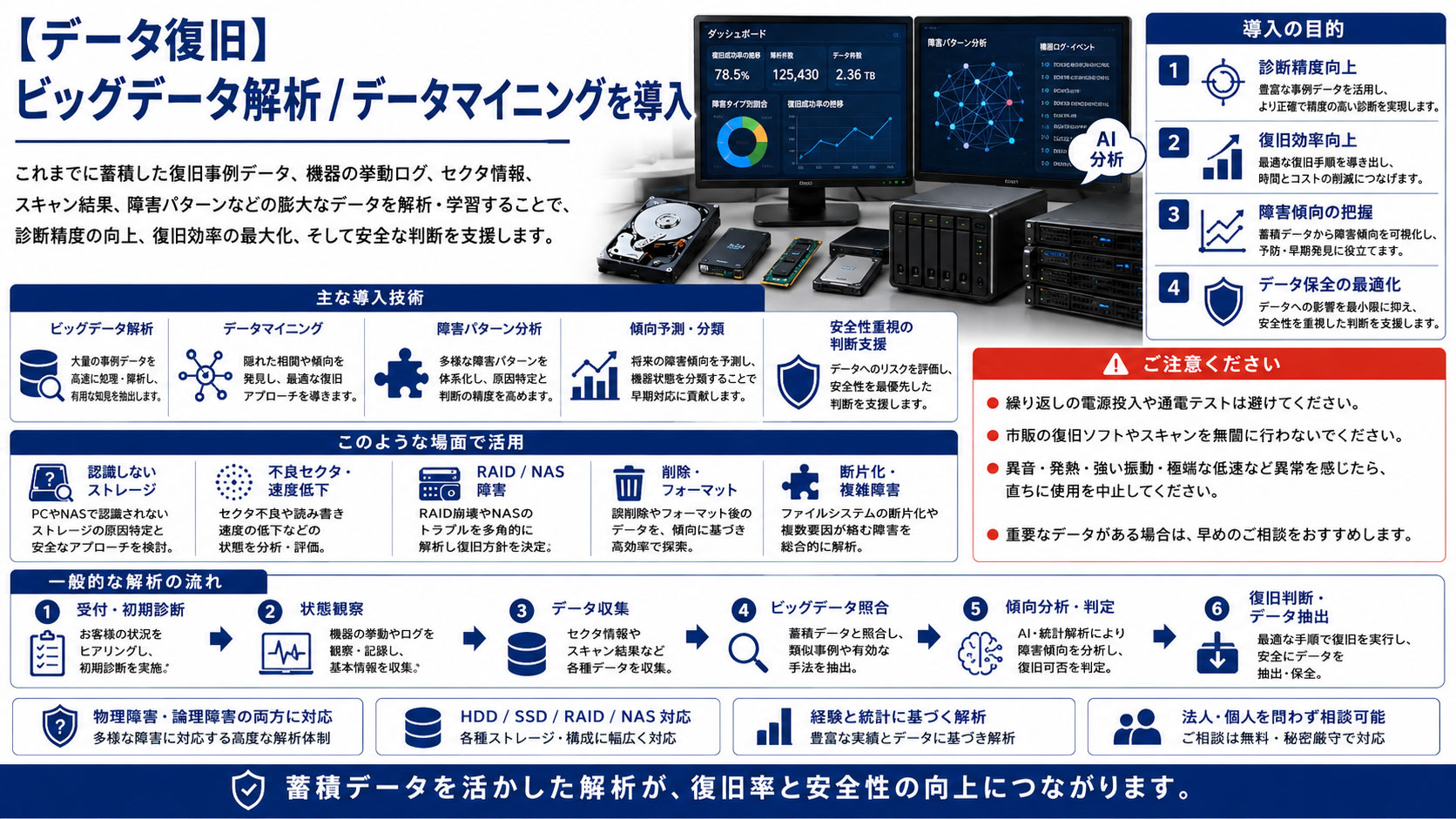

データ復旧サービス 蓄積した復旧事例・挙動ログ・障害パターン・症例
量産されたドライブは、同じ製品や同じ系列であれば、故障の傾向にも一定の共通性が現れることがあります。
当サービスでは、長年のデータ復旧作業を通じて、ドライブの故障状態や挙動には、製品構造や使用状況に応じた一定のパターンが存在することを確認してきました。
壊れかけたドライブは、状態を確認するためのアクセスだけでも負担となる場合があります。
そして、その状態変化は、そのまま状態悪化につながることもあります。
そのため、復旧作業では「その場で試してみる」だけでは不十分です。
できる限り状態を悪化させずに復旧するには、過去の復旧事例、挙動ログ、障害パターン、症例を正しく活用する必要があります。
当サービスでは、20年以上にわたって蓄積してきた復旧事例をもとに、故障時の挙動や読み取り傾向を整理してきました。
さらに、それらの事例を単なる経験として残すのではなく、数理的に整理し、統計情報として活用できる形へ置き換える技術開発も進めてきました。
「復旧できました」で終わらせてしまえば、その経験は次につながりません。
重要なのは、なぜ復旧できたのか、どのような挙動を示していたのか、どの条件で状態が悪化したのかを蓄積し、次の復旧判断に活かすことです。
このような症例を積み重ね、解析し、実際の復旧作業に反映することで、より安全で精度の高いデータ復旧が可能になります。
ビッグデータ解析 / データマイニングを導入 並列処理で大容量に対応
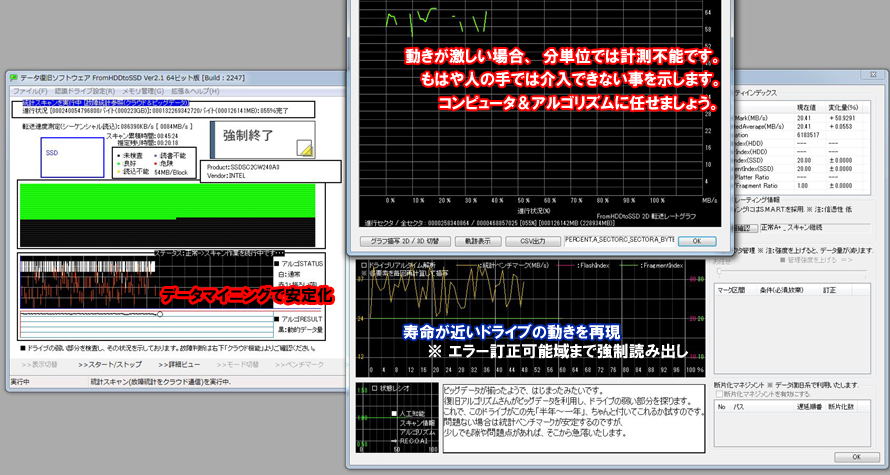
コンピュータの躍進により大量の統計データを解析できるようになりました。
そこから有用な情報の取り出しと無用な情報の破棄を行うデータマイニングを実施可能となりました。
不要な情報の破棄
最適解を統計データから導く
状態悪化への移行時間は3秒程度が限界です。そのため3秒以内(平均1秒以内)を目安に回避させる技術を開発しております。
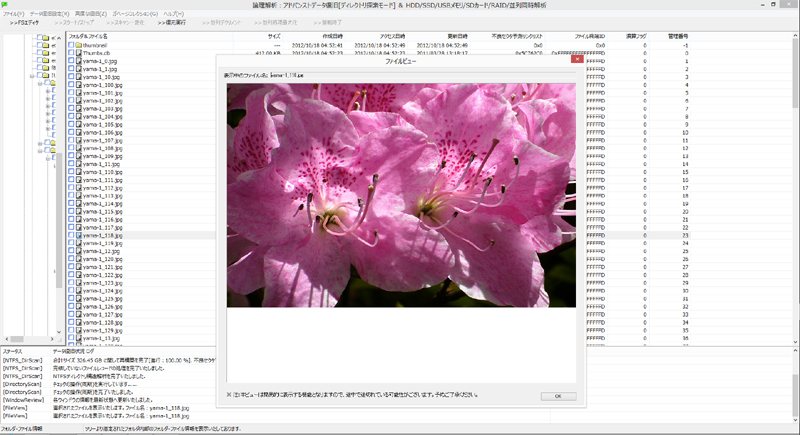
最近の傾向:製造2年以内のドライブ故障が増加中
近年、製造から2年以内のドライブにおける故障事例が急増しています。対象はパソコン内蔵型・外付けHDD・NAS・RAID構成さらにはTeraStationなど多種多様な環境で共通の障害傾向が見られドライブ自体の設計・製造レベルに起因する可能性も浮上しております。
クリーンルーム作業後でも難航する制御
これら新型ドライブの故障においてはクリーンルーム作業で内部修復を行った後でも動作の安定性や制御幅が極めて限定され従来の方法では対応が難しいケースが増えています。特にファームウェアやコントローラ内部の仕様が厳格で一部の動作すらブロックされる構造となっているため復旧にはより高度な対応が求められます。
独自開発装置による自動制御・復旧へ
弊社ではこのような困難な状況にも対応すべくWindowsベースの制御に依存せず自社開発の専用装置による部分的な自動制御と制御系の独立化を進めています。これにより従来では復旧が困難だった新型ドライブに対しても物理制御の再構築によるデータ復旧の道が開かれつつあります。
短期間で故障するケースが増えている現代のストレージ環境に対しても弊社では柔軟かつ高度な技術で対応しております。「クリーンルーム作業 + 独自制御技術」の組み合わせにより最も困難とされる復旧事例にも積極的に取り組んでおります。
