
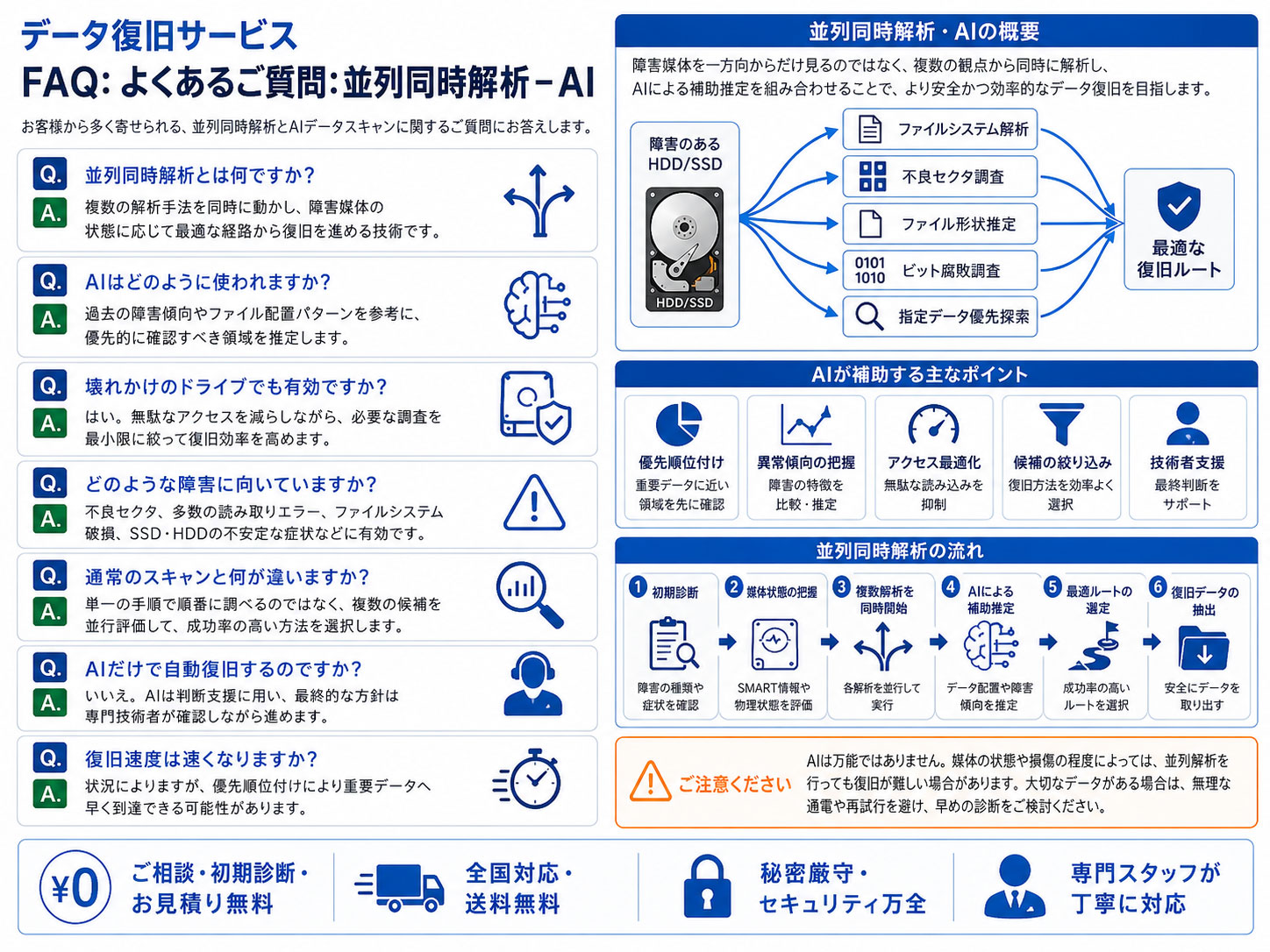
よくあるご質問: 並列同時解析 – AI
上記の内容以外にも、ご不明な点や気になることがございましたらどうぞお気軽にお問い合わせください。
並列同時解析
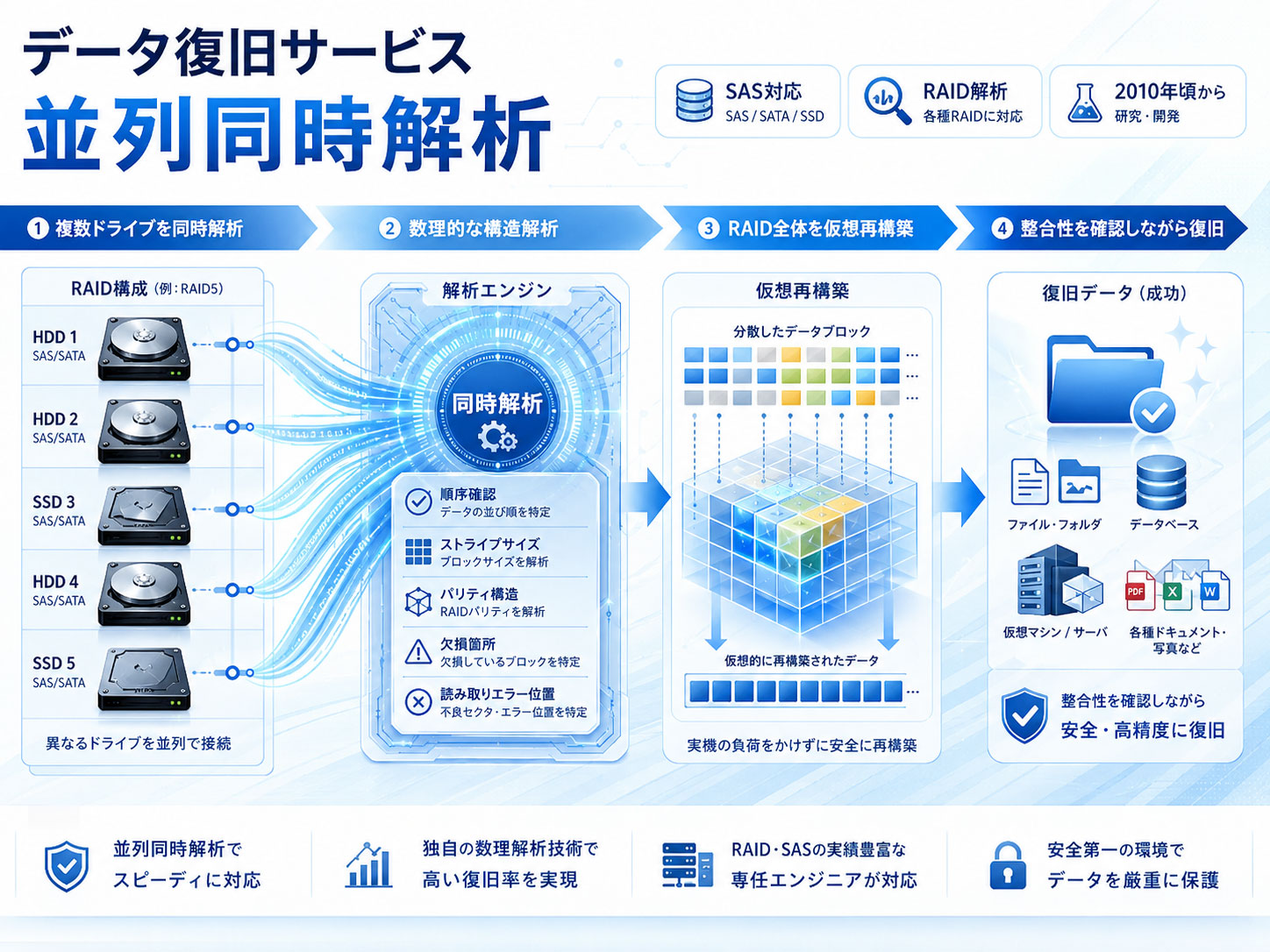
並列同時解析は、主にRAID構成のデータ復旧で活用している解析技術です。
RAIDでは、複数のドライブが同時に動作し、データを分散・冗長化しながら記録しています。
そのため、復旧作業でも、参加している各ドライブを個別に見るだけでは不十分です。
重要なのは、複数のドライブを並列的に解析し、それぞれの状態やデータ配置を照合しながら、全体構造を再構築していくことです。
当サービスでは、RAIDに参加している各ドライブを同時に解析し、解析結果をもとに仮想的な再構築を進めます。
つまり、単にドライブごとのデータを読み出すのではなく、解析と再構築を並行して行うことで、RAID全体としての整合性を確認しながら復旧を進めます。
この一連の処理では、各ドライブの順序、ストライプサイズ、パリティ構造、欠損箇所、読み取りエラーの位置などを正確に扱う必要があります。
そのため、経験だけに頼るのではなく、数理的な処理によって確実に構造を解析していくことが重要になります。
この並列同時解析は、2010年頃から研究・開発を進めてきた技術です。
現在では、一般的なRAID構成だけでなく、SASドライブを含む特殊な構成や複雑なストレージ環境にも柔軟に対応できるよう改良を重ねています。
RAID復旧では、構成を誤って再構築すると、復旧結果の整合性が大きく崩れるおそれがあります。
そのため、複数ドライブを同時に解析し、全体の構造を正確に把握しながら進めることが、復旧精度を高めるうえで重要です。
当サービスでは、並列同時解析によってRAID全体の状態を把握し、十分な解析性能を保ちながら、安全で精度の高いデータ復旧を目指しています。
2014年:ドライブリアルタイム解析を導入
2014年11月よりデータマイニングを開始いたしました。そして2015年6月より大容量ドライブの復旧向けにR.E.C.O.A.I.(人工知能)を本格的に稼動いたしました。膨大なセクタ数を間違う事なく正確に進めていく装置となっておりまして特に3.0TB以上の復旧には欠かせない存在となりました。
Q1, 並列処理による利点とは?
近年のパソコンは「マルチコア」と呼ばれる複数の実行コアを物理的に持っております。
これにより重い負荷を与えましても分散する事により処理速度を保てる特性がございます。ただし分散させるには「タイミング」が非常に重要となりまして例として同じ要素を別々に同時取得してしまうと本来の処理とは異なる結果につながってしまいます。
しかしながらその点に注意してロックをかけ過ぎると今度は全体処理性能が大幅に低下する難点がございます。
そのため、それらのバランスを取りながら速度と復旧精度を追求する解析手法となっております。上手く組みますと負荷が重い処理でも解析速度が落ちないため納期を短縮することが実現しております。
Q2, 時間よりも復旧率を優先できますか?
問題なく対応可能です。ヘッド系統の障害では最短の納期にて最大の復旧率を出す事が可能です。
しかしながらプラッタ系統の障害(プラッタ歪み)ではやはりお時間をかけた方が復旧率が良くなります。このような場合ではデータ納品を複数回に分けまして徐々にデータ納品量を増やしていく方式を取ります。
Q3, RAIDやサーバに対しても高精度で対応できますか?
並列同時解析は並列化されている「RAID系統」を得意とする設計です。RAIDを構成する複数のHDDを同時に安定化制御および並列に同時スキャンしつつ作業用エリアへスキャン結果を結合(RAIDイメージ)そのイメージを同時に領域解析などもできてしまいます。
近年、容量が増加するストレージを復旧するには並列処理を基本とする技術が主要となってきております。
Q4, ドライブリアルタイム解析に導入されるビッグデータはどのような働きをいたしますか?
ドライブ故障統計の集まりなので不良セクタ化の場所に関する予想を立て易くなっております。
データ復旧では、このような不良セクタを出来る限り避けてリスクを低下させる必要がございますので、復旧率向上に貢献しております。


