コンテンツへスキップ

分散型ドライブ検査・復旧システム
分散型ドライブ検査・復旧システム
【データ復旧】FromHDDtoSSD 復旧設定 復旧系スキャン
- ホームページ >
- 【データ復旧】FromHDDtoSSD 復旧設定 復旧系スキャン
復旧設定:復旧系スキャンオプション解説
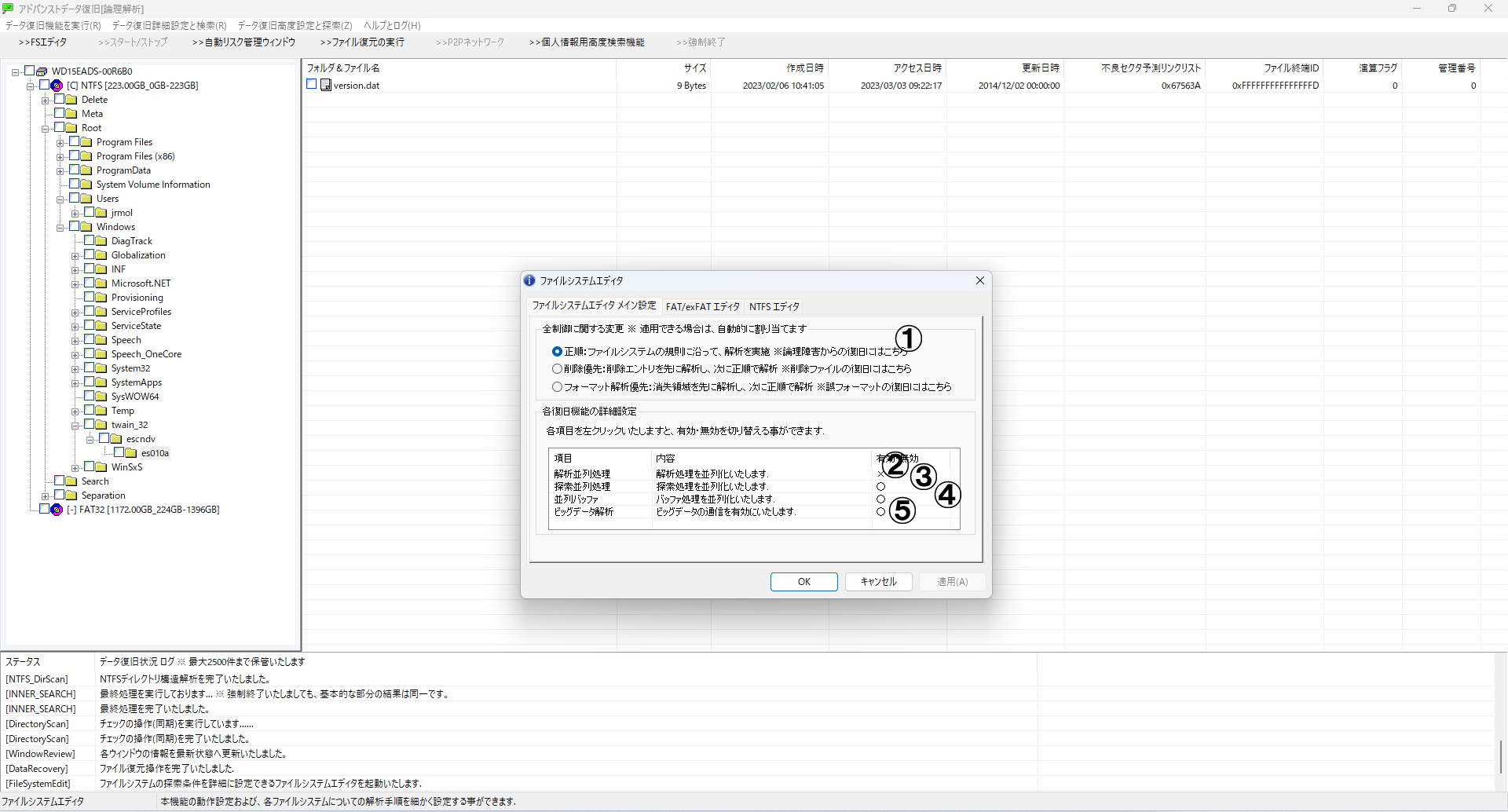
■ A. 探索順序と処理速度の最適化
- 1番:探索順序の切り替え
損傷状況によっては探索順序を変更することで有効な結果が得られる場合があります。
- 2番・3番・4番:処理速度に関する設定
- 解析並列処理:ファイル構造解析を並列で実施。
- 探索並列処理:解析に必要な情報収集処理を並列化。
- 並列バッファ:バッファ処理を複数化しスキャン中の待機を削減します。
- 5番:ビッグデータオプション
AIベースのビッグデータ予測を活用しスキャン量を大幅に削減します。特にメタデータ探索に対する精度が向上します。
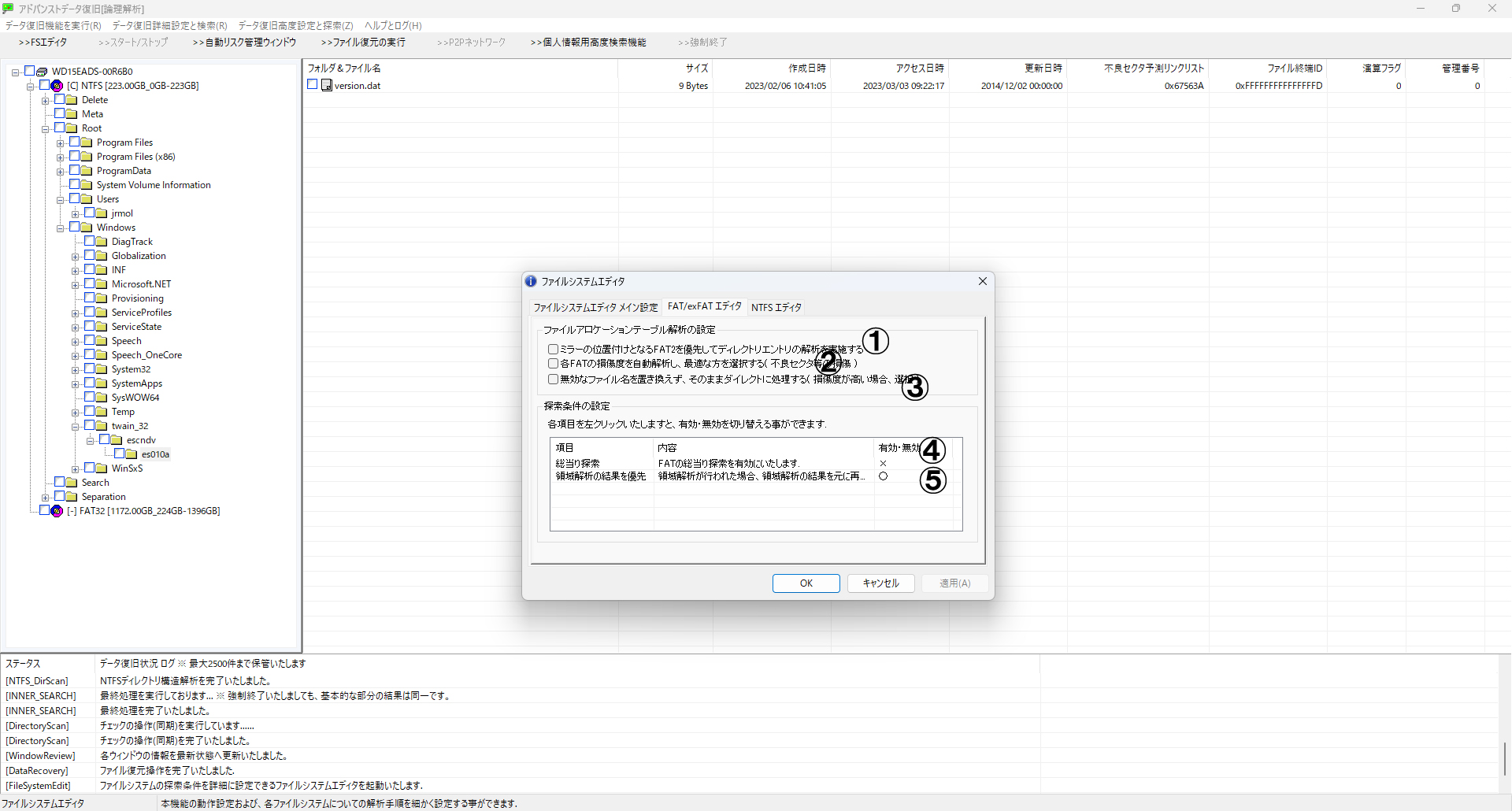
■ B. FATファイルシステムに対する設定
- 1番:FAT2を優先する
通常はFAT1が優先されますがミラーであるFAT2を優先的に使用します。
- 2番:FAT1・FAT2から最適選択
両テーブルを評価しもっとも信頼性の高い構造を採用します。
- 3番:無効なファイル名の保持
復旧結果に誤置換が起きないよう無効な名前もそのまま出力します。
- 4番:総当たり探索の有効化
FAT情報が完全に損傷している際に有効です。データ配置を総当りで試行し、復旧を図ります。
- 5番:領域解析の結果を優先
通常のFAT構造では得られない情報をもとに解析を行います。時間はかかりますが、困難なケースでは効果的です。
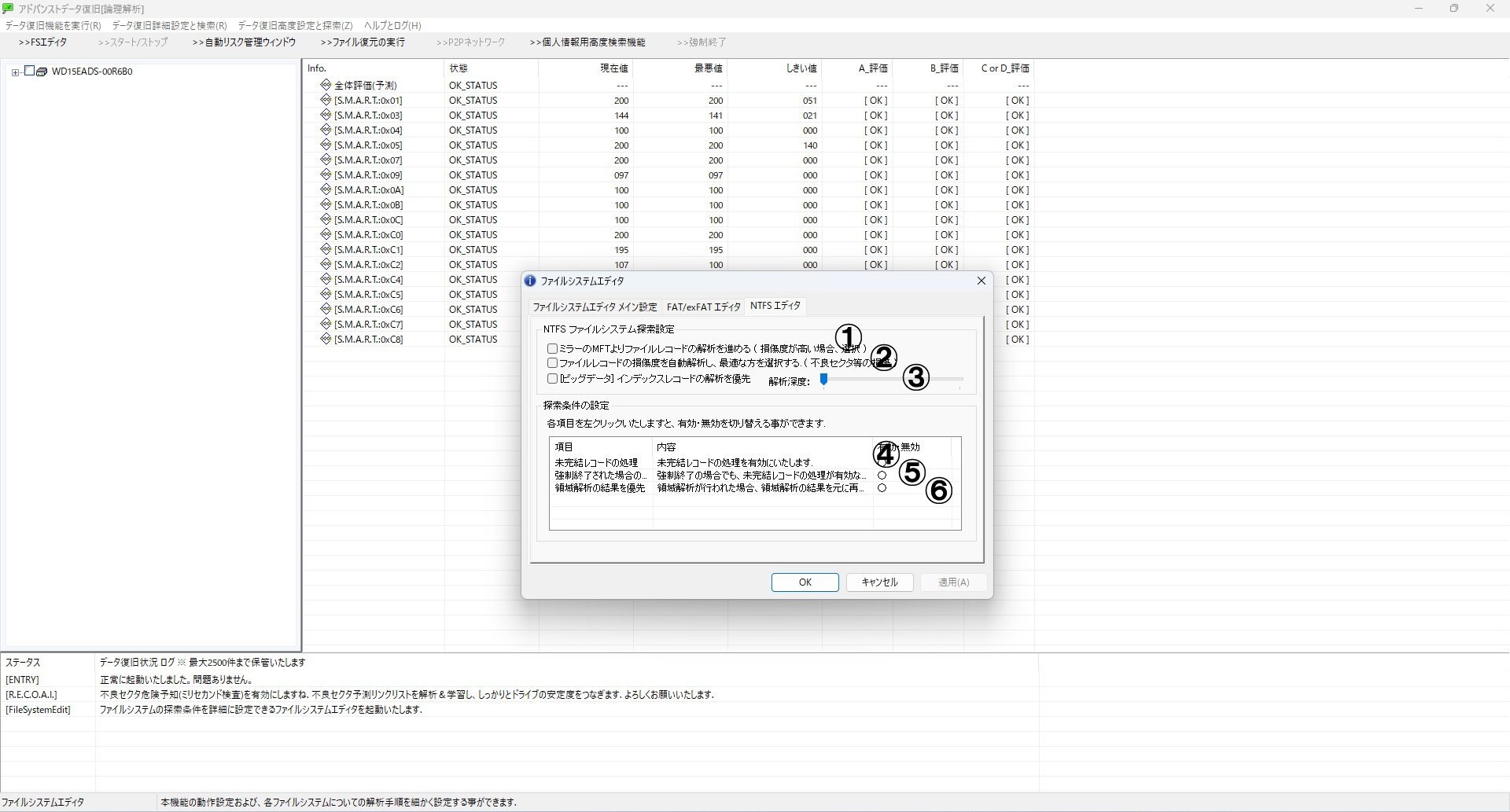
■ C. NTFSファイルシステムに対する設定
- 1番:ミラーMFTの優先使用
メインのMFTに損傷がある場合でもバックアップであるミラーを優先します。
- 2番:損傷度の自動選別
ファイルレコードの状態を解析し問題ない部分だけを優先的に取り込む動作です。
- 3番:ビッグデータによる深度最適化
スキャン深度をスライダーで調整可能。深く設定することで復旧精度が向上します(処理時間が長くなります)。
- 4番:未完結レコード解析の有効化
断片化や圧縮によりファイル情報が一つのレコードに収まらない場合に対応します。
- 5番:強制終了後の未完結レコード処理
スキャンが途中で終了した場合でも未完結レコードを解析し復旧を試みます。
- 6番:領域解析結果を用いた構造解析
MFTに依存せず、領域解析から得た情報のみを使って復旧を実行します。NTFS構造が壊滅的に損傷している際に有効です。
補足
- 領域解析が行われていない状態では「領域解析優先」設定は無効扱いとなります。
- すべての設定は対象ドライブや障害状況に応じて最適化可能です。初期診断で得られた情報をもとに必要なオプションを選択してください。