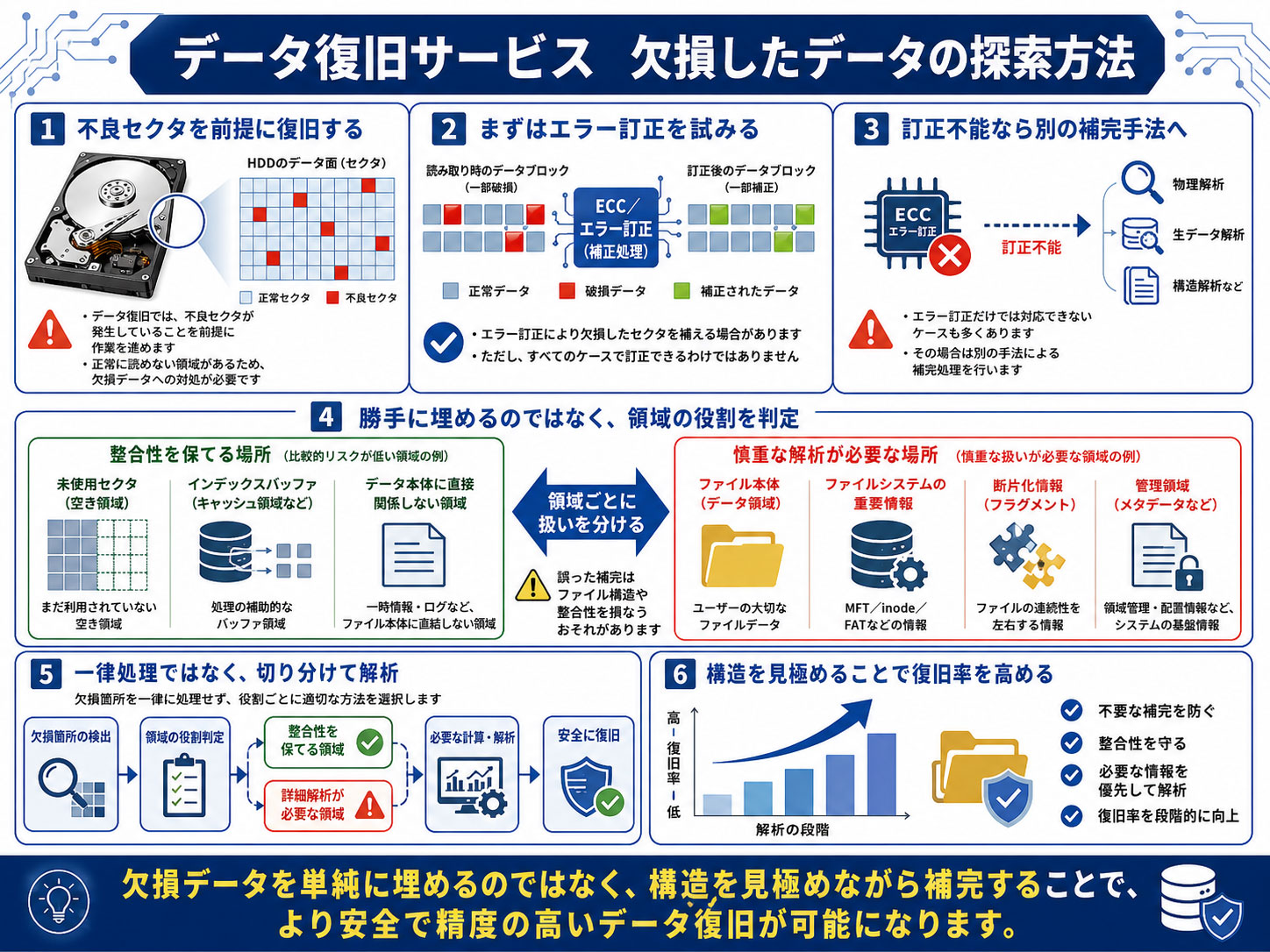
データ復旧サービス 欠損したデータの探索方法
データ復旧を必要とするドライブでは、不良セクタが発生していることを前提に作業を進める必要があります。
不良セクタがある場合、その部分のデータは正常に読み出せないため、エラー訂正などの手法によって欠損したセクタを補う必要があります。
しかし、実際の復旧現場では、エラー訂正だけでは対応できないケースも多くあります。
エラー訂正が不能な状態になっている場合、その処理だけに頼ったデータ復旧では十分に対応できません。
そこで当サービスでは、欠損したセクタに対して、別の手法による補完処理を行います。
ただし、情報が失われてしまった場所に対して、勝手にデータを追加するわけにはいきません。
誤った補完を行えば、ファイル構造やデータの整合性を損なうおそれがあるためです。
そのため重要になるのが、失われても整合性を保てる場所と、解析が必須となる場所を明確に分けて考えることです。
失われても整合性を保てる場所とは、たとえば未使用セクタや、データ本体に直接関係しないインデックスバッファのような領域です。
これらは、欠損していてもファイルの実データそのものに直接影響しない場合があります。
一方で、ファイル本体、ファイルシステムの重要情報、断片化情報、管理領域などに関わる箇所は、慎重な解析が必要です。
このような領域を安易に補完してしまうと、復旧結果の整合性が崩れる可能性があります。
そのため当サービスでは、欠損箇所を一律に処理するのではなく、まず領域の役割を判定します。
そのうえで、整合性を保てる箇所と、詳細解析が必要な箇所を切り分け、必要な計算と解析を行いながら復旧を進めます。
このように、欠損したデータを単純に埋めるのではなく、構造を見極めながら処理することで、復旧率を段階的に高めることが可能になります。
統計処理の導入
データ復旧の解析では「手数」の考え方がとても大切な要素となっております。
例えば同じデータを取得する場合であっても複数の方法が存在するものとします。この場合は正常なドライブならば「どちらでもいい(ファイルシステムが成立)」となります。しかしデータ復旧の現場では「手数」が少ない方を優先的に選ぶ必要があります。
ここで「優先的」としたのは「手数」が少ない手法であってもリスクが高い場合にはあえて「手数」が多い方を選択する場合があるためです。
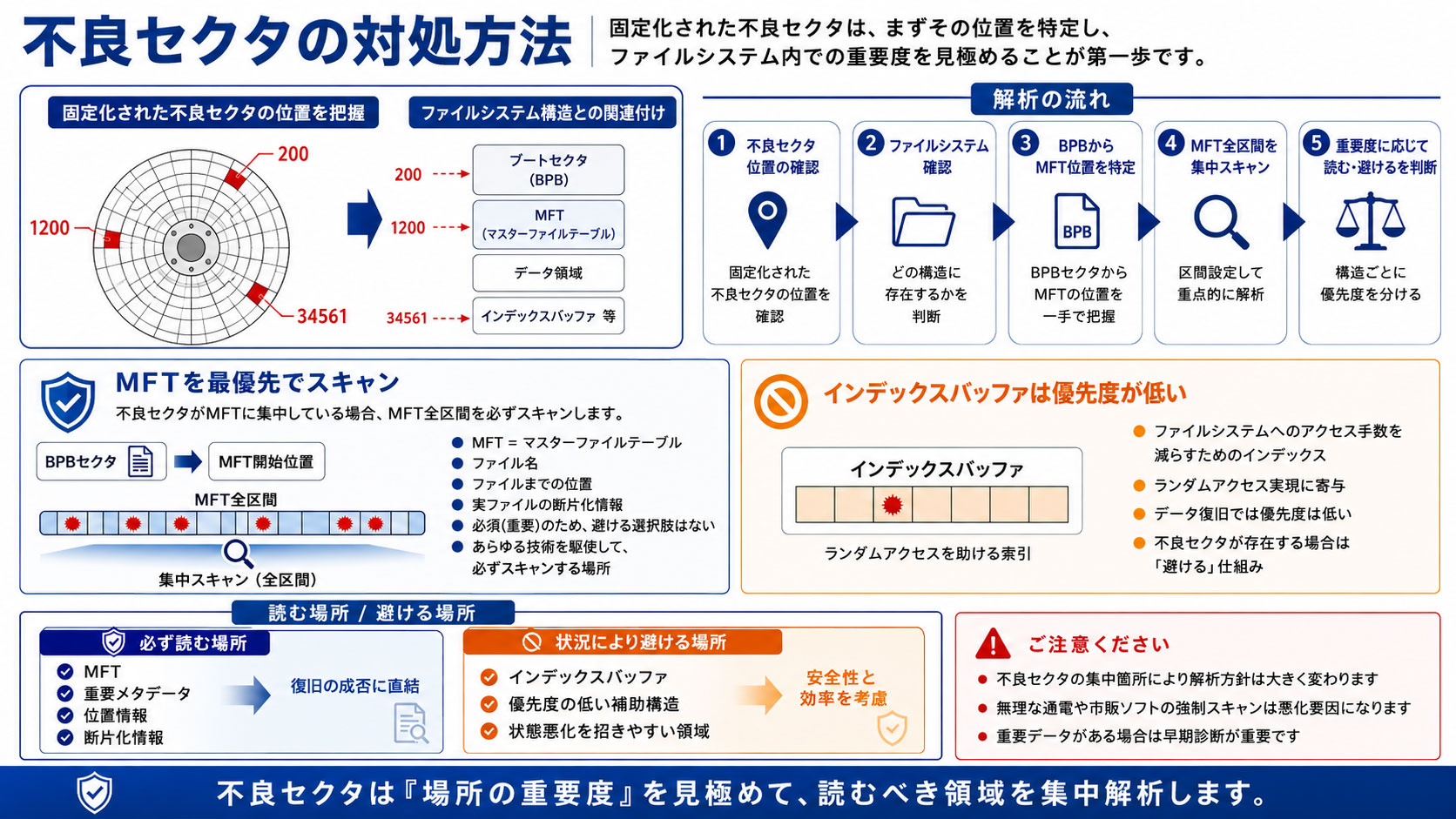
固定化される不良セクタ
不良セクタが発生した場合であっても一度発生した不良セクタが「固定化」されるなら、不良セクタの回避方法については、それらをスキャン区間に設定しその区間内を同じルールに固定化して不良セクタを避けることを実現いたします。
不良セクタの対処方法
不良セクタが「200」「1200」「34561」で発生している場合を考えてみます。固定化されている場合、基本的にこれらのセクタの位置が「どこに存在するのか」を判断いたします。
次にファイルシステムを確認いたします。そしてこれらが「MFT」と呼ばれる「マスターファイルテーブル」に多く発生している点をつきとめます。そこでこの「マスターファイルテーブル」の位置は「BPB」と呼ばれるセクタから「一手」で判明できますからそこを「区間」に設定してこのような不良セクタが存在するとみるスキャン方法で「MFT」全区間をスキャンします。ところで「MFT」の必要性です。
MFTには「ファイル名」「ファイルまでの位置」「実ファイルの断片化性」が含まれ「必須(重要)」です。そのため「避ける」という選択肢はありません。あらゆる技術を駆使して、必ずスキャンする場所となっております。
逆にその不良セクタが「インデックスバッファ」だった場合です。この「インデックスバッファ」はファイルシステムへのアクセスの手数を減らすためのインデックスです。これにより「ランダムアクセスが実現」できているのですがデータ復旧では優先度は低いためここに不良セクタが一つでも存在する場合は「避ける」仕組みです。
必要なセクタ・そうではないセクタ。それらを区別してスキャンする方法となっております。