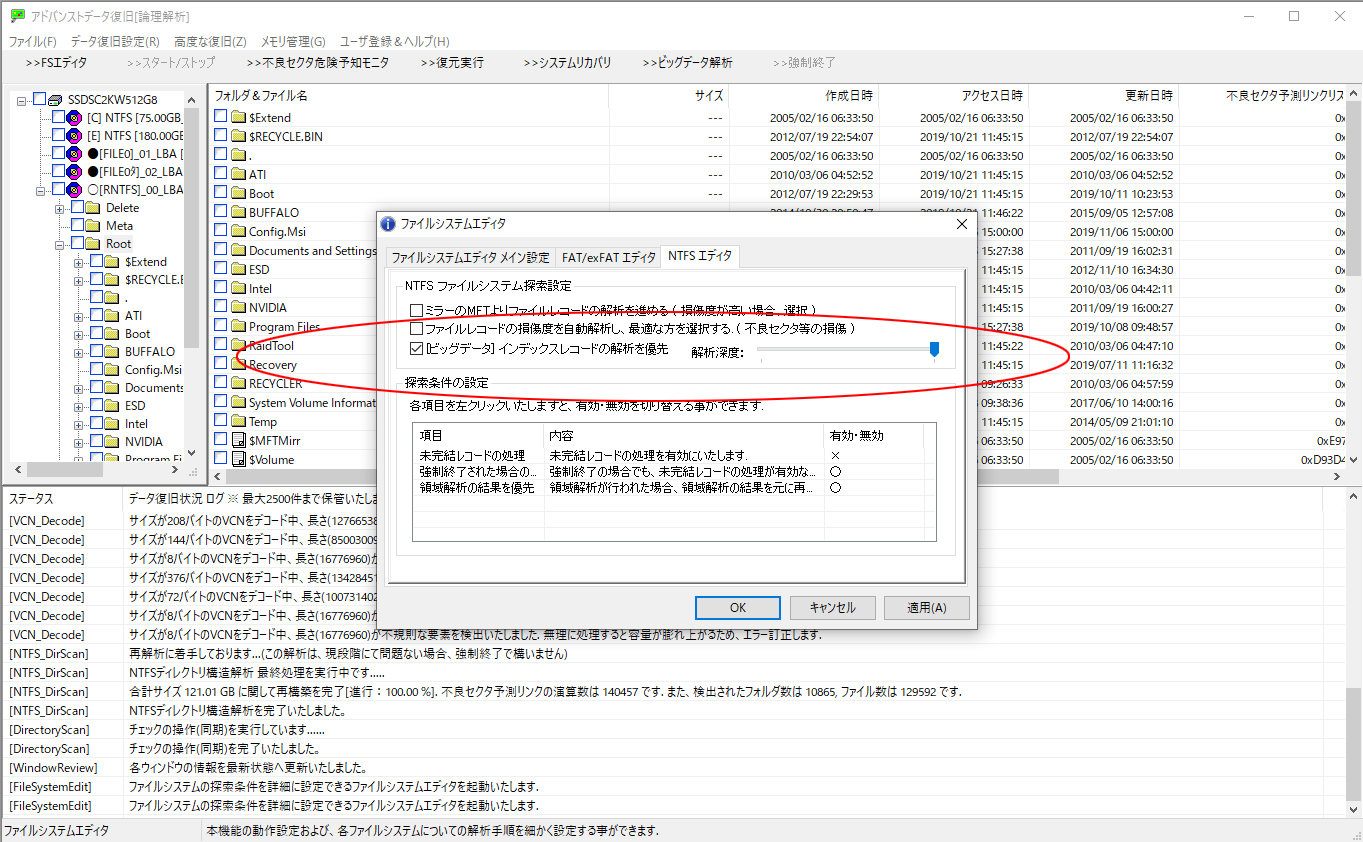
危険な不良セクタに接触する機会を減らす
→効果を上げるにはスキャンを少なくします。
危険な不良セクタを回避する点も重要なのですがそれ以上に大事なのが接触する機会を減らす事です不良セクタを回避できてもその回数が増加すればそれに従ってリスクが増加いたします。また接触を減らせれば回避自体の機会を減らせますのでリスクが低下いたします。
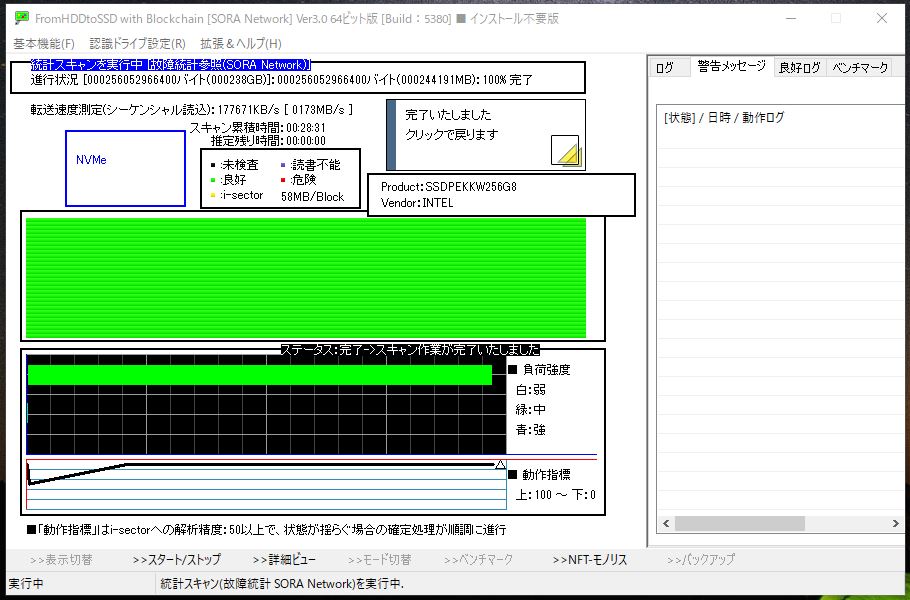
領域解析スキャン(クラスタスキャン)
データ復旧系ソフトは全セクタを解析して結果を出す領域解析(クラスタスキャン)と呼ばれる機能がございます。全セクタをスキャン後に再度各セクタにアクセスを試みてデータを取り出しますのでスキャン量が非常に大きくなります。正常なドライブまたは壊れても安定したドライブならば問題ないのですがそのような都合の良いドライブは中々ありません。さらに2.0T以上の大容量ドライブは普通に数十時間を要する場合も珍しくありません。
スキャン量が増加するので危険なセクタへの接触機会が増加してしまいます。
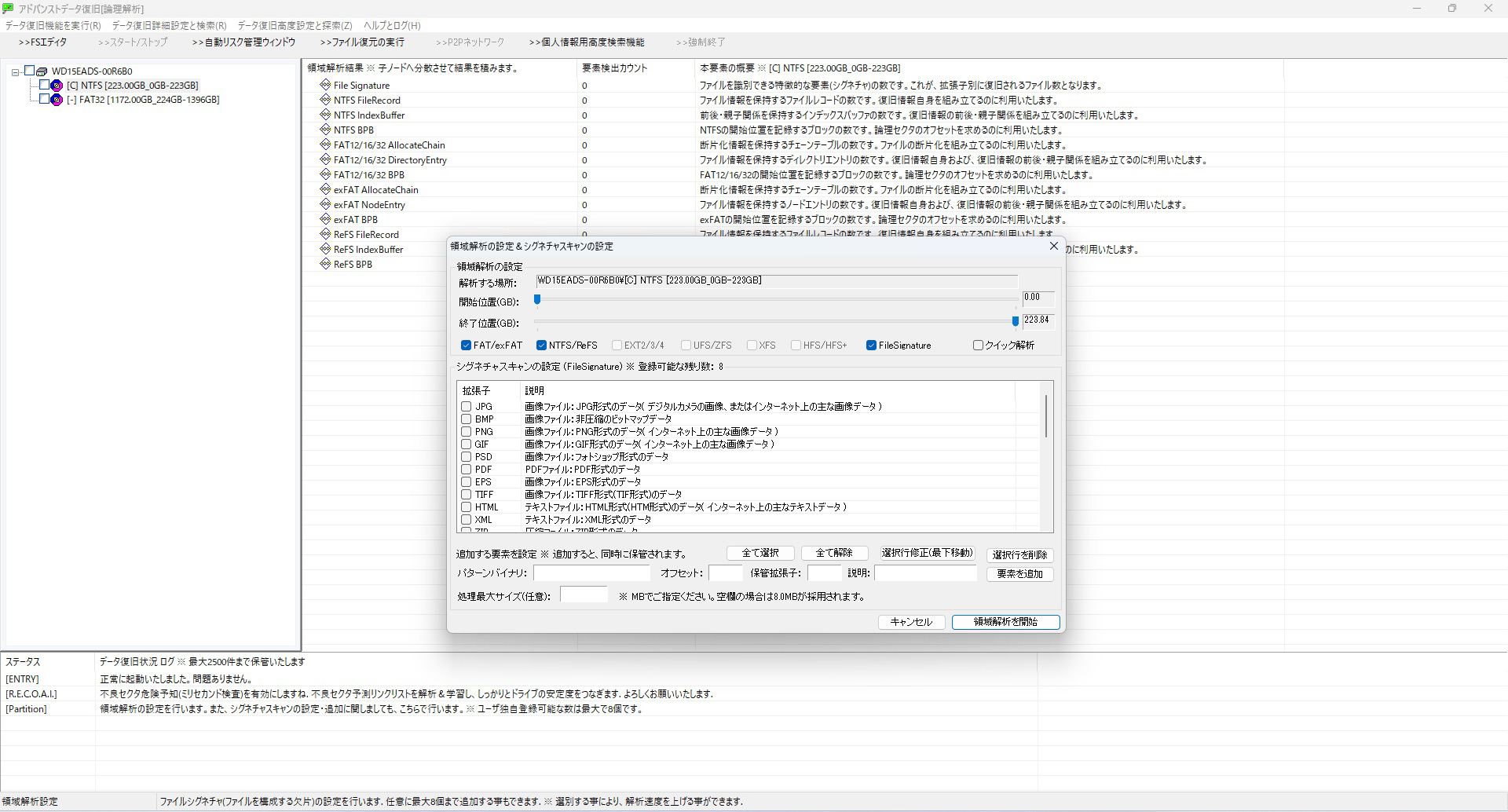
スキャン量を削減 ビッグデータ構造解析
それでもディレクトリ構造解析で解析できない場合は事前に領域解析(クラスタスキャン)が必要です。しかしファイルシステムに形状の概念を導入すると統計的に必要がないセクタが事前にわかります。データスキャンの量を削るだけ。色々な手法を考え投入していきます。