
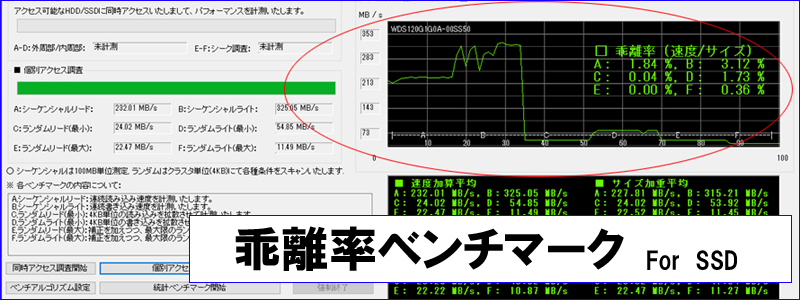
各モデルのベンチマークに関する状態を標本にしてブロックチェーンに記録し各モデル別(またはメーカ別)に母集団の特徴付けを実施いたします。そうして得られた統計を参照しそこから大幅な乖離がみられる場合には確信を持って「事前」に「交換推薦」を出すことができる仕組みをSORA blockchainで確立いたします。
Transcend 240GB SSD
TS240GSSD220S
| パフォーマンス | 3 / 5 |
| 動作安定度 | 2 / 5 |
| コスト面 | 3 / 5 |
| 耐久性(通常利用) | 3 / 5 |
| 耐久性(書き込み回数増) | 3 / 5 |
| 総合評価 | 14 / 25 |

Benchmark Test 1
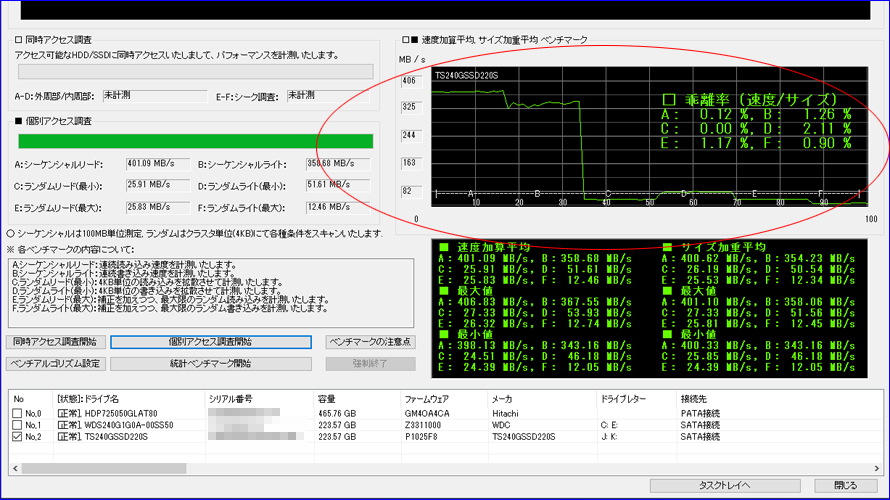
Benchmark Test 2
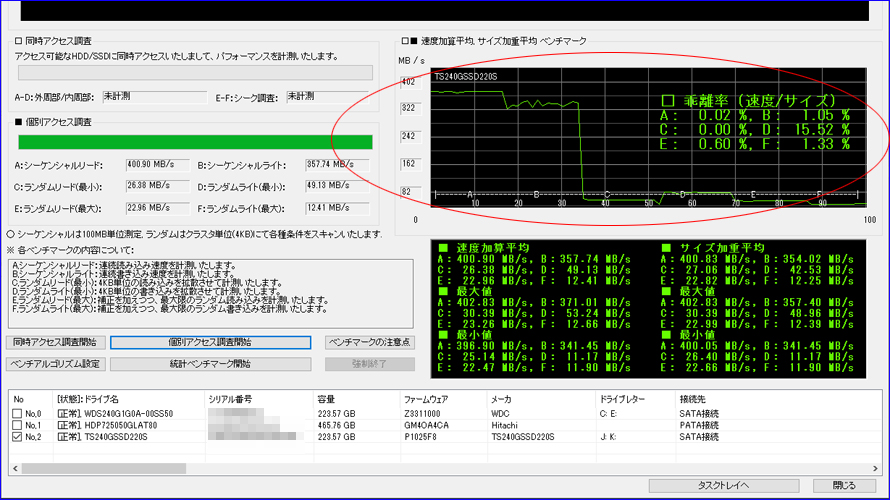
Benchmark Test 3
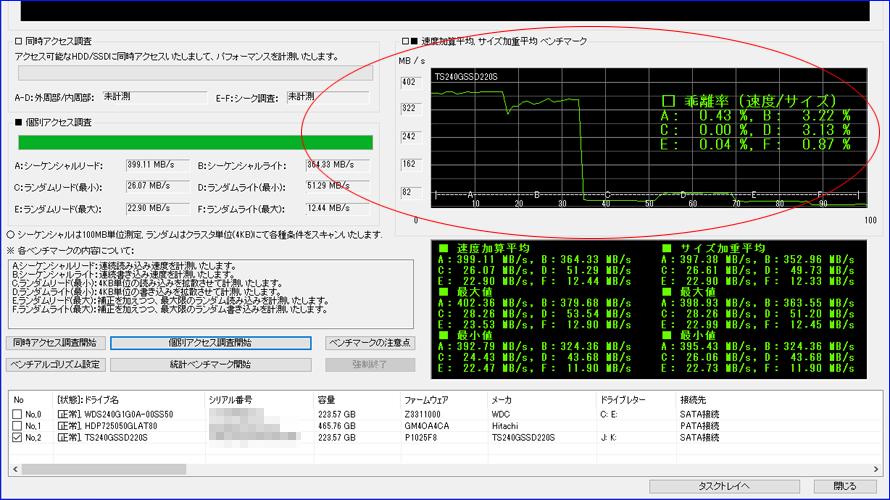
Benchmark Test 4
Benchmark Test 5
Benchmark Test 6
Benchmark Test 7
Benchmark Test 8
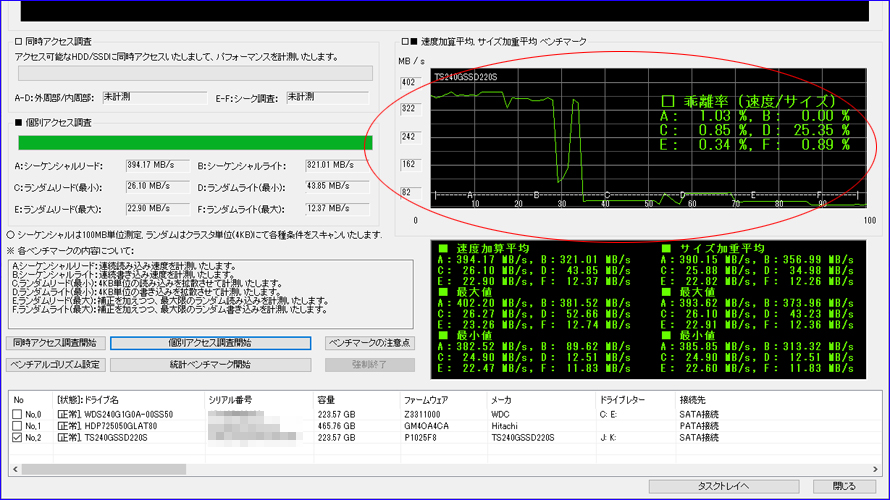
Benchmark Test 9
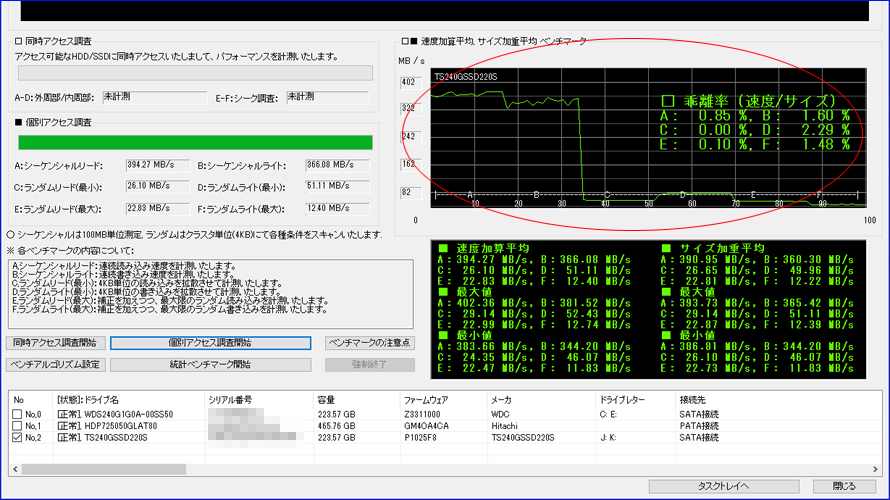
Benchmark Test 10
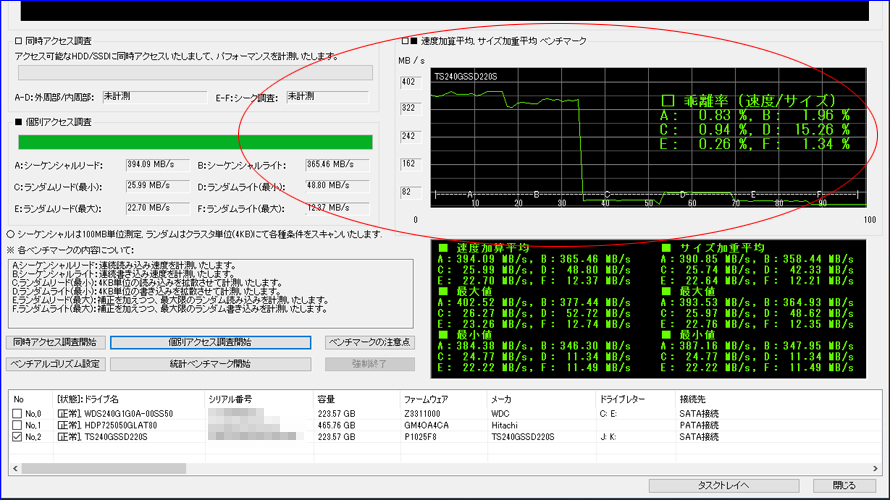
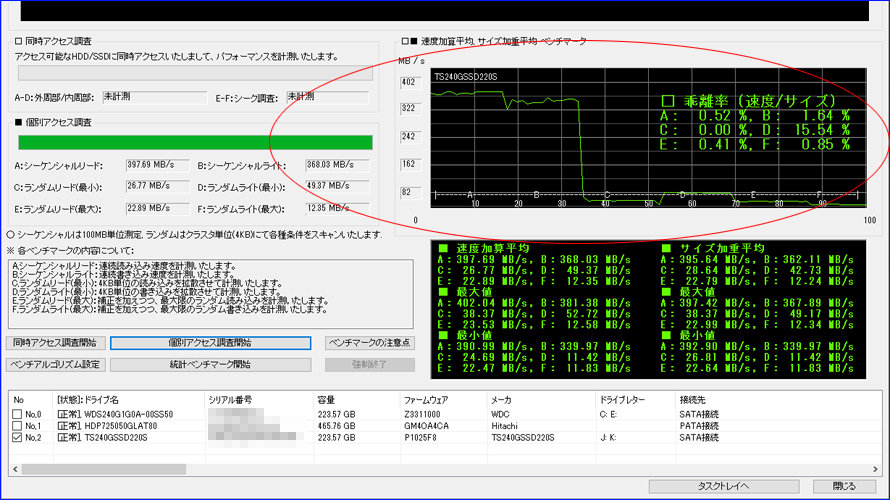
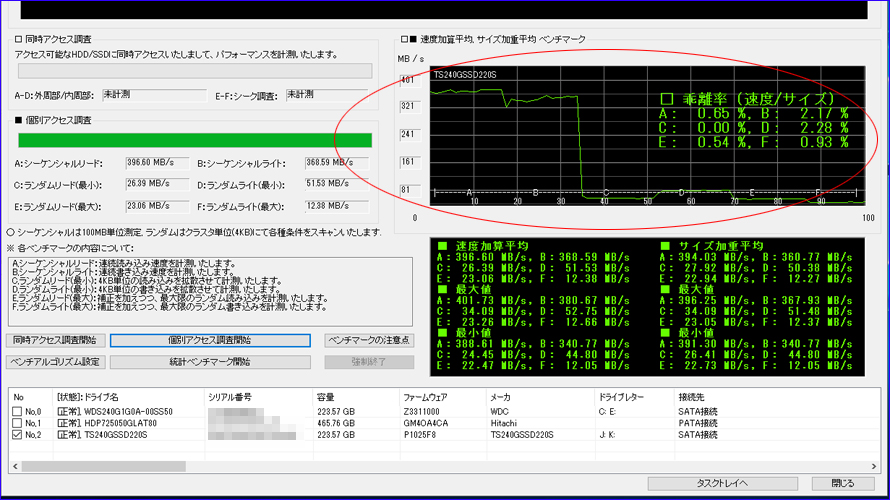
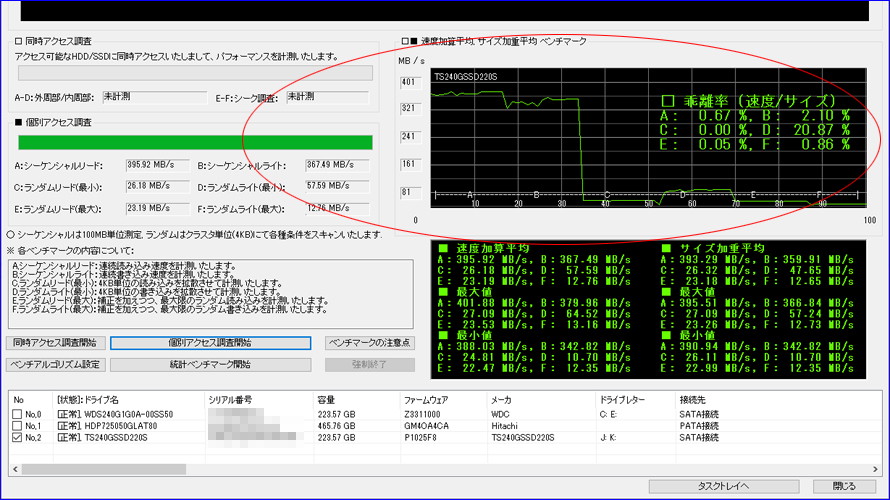
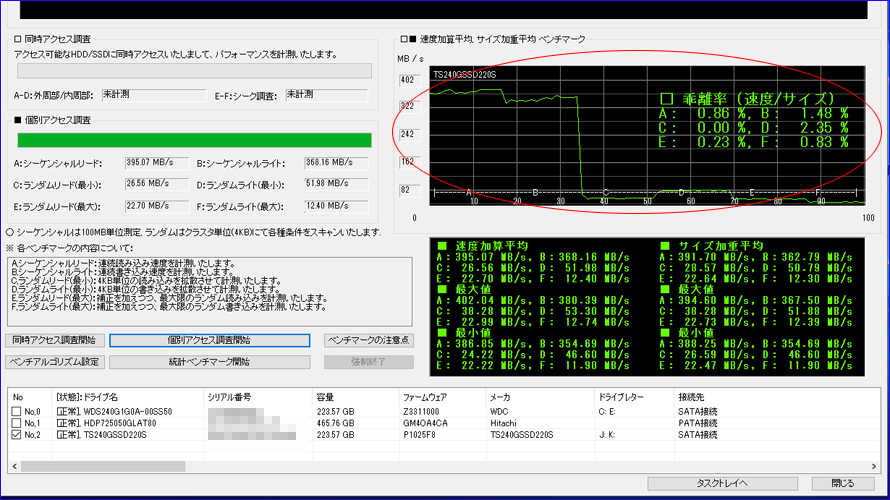
複数回を続けて実施いたしました結果、偶数回に限って赤丸部分のテストDの乖離率が大幅に上昇する現象を検出いたしました。 また、計10回実施いたしましてきちっと5回揃いましたので、偶然ではないと判断いたしました。
テストDはランダムライト最小で、4KB単位を-3σ~+3σの負荷でベンチマークいたします。このため、-1σ~-3σの時に溜め込んだ仕事をまとめて放出するアルゴリズムのようです。この放出時は加重平均がドスンと落ち込みますので、それが乖離率として出てきております。それにしても「交互に出現」というのがとても興味深いです。
ベンチマークの測定時間は、だいたい数分ゆえに、その時間は何とか持ちこたえて、まとめて後から放出・・という感じでしょうか。 つまり、ベンチマーク重視のような感じです。
ただ、加重平均のドスンは論理障害などの誘発につながりますので、できれば分散放出の方が良いのです。分散放出の場合はベンチマーク中に足を引っ張る処理(グラフが乱れる等)が出てきてしまいますが、実用面では何の影響もありません。