
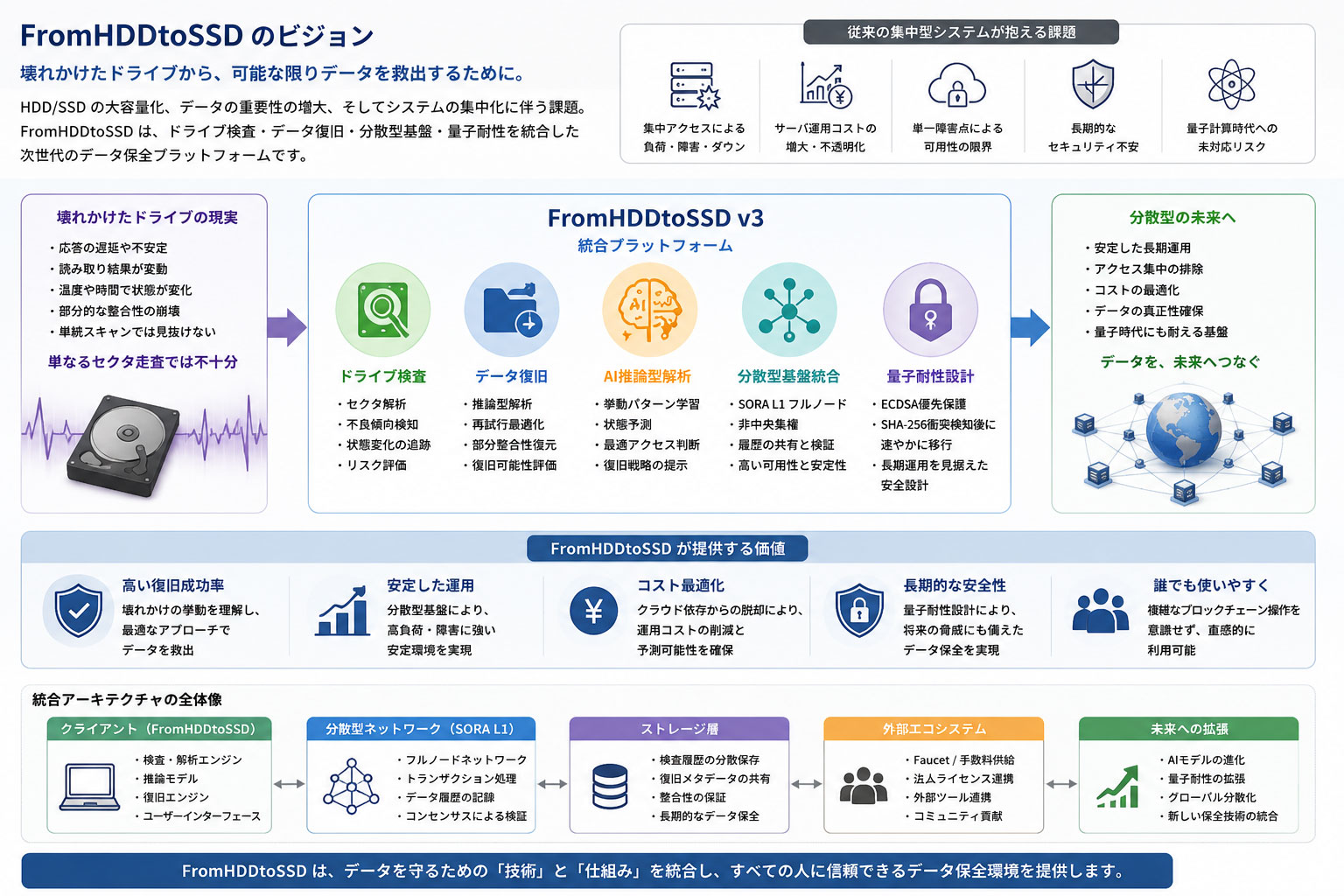
- Introduction
- 第一章 なぜ、データの最小単位「セクタ」を走査するだけでは、検査も復旧も成り立たないのか
- 第二章 セクタを読むだけでは終わらない ――FromHDDtoSSD の多層型ドライブ検査
- 第三章 完全スキャンベースの設計
- 第四章 同時検査による大容量ドライブ対応
- 第五章 将来的な不良化予測
- 第六章 SSDの劣化状態の数値化
- 第七章 単なるスキャンソフトではなく、状態解析基盤へ
- 第八章 AI完全自動データ復旧システムと、従来型マニュアル復旧操作の統合
- 第九章 壊れかけドライブへの配慮
- 第十章 データ復旧を、より安全で扱いやすいものへ
- 第十一章 SORA L1との連携 ブロックチェーンによる分散型システムの構築
- 第十二章 中央集権型システムの限界
- 第十三章 FromHDDtoSSD v3での統合
- 第十四章 手数料設計
- 第十五章 分散型データ保全基盤へ
Introduction
近年、HDDおよびSSDの大容量化は急速に進み、それに伴い、ドライブ検査およびデータ復旧に求められる負荷も飛躍的に増加しています。
従来のドライブ検査ソフトウェアは、単純なセクタ走査やファイルシステム解析を中心として構築されていました。しかし、実際の故障現場では、それだけでは十分とは言えません。
壊れかけたドライブは、単純な読み取り不能だけではなく、
- 応答遅延
- 不安定なセクタ挙動
- 一時的な応答復帰
- 熱による状態変化
- 部分的な整合性崩壊
など、複雑な挙動を示します。
FromHDDtoSSD は、そのような「壊れかけ」の状態に対処するため、単なるドライブ走査ではなく、推論型解析・復旧支援・分散型処理を統合したソフトウェアとして設計されました。
さらに、本プロジェクトは単体ソフトウェアに留まりません。
従来クラウド版として提供していた検査基盤では、利用者増加に伴う集中アクセス問題、サーバ負荷、運用コスト増加など、中央集権型システム特有の課題が顕在化しました。
そのため、本プロジェクトでは、これらの問題を根本的に解決するために、分散型ブロックチェーン基盤「SORA L1」を統合しています。
FromHDDtoSSD v3 では、この分散型基盤を内部統合することで、利用者が複雑なブロックチェーン操作を意識することなく、非中央集権型の安定動作を利用可能としました。
また、本プロジェクトでは長期運用を見据え、量子計算時代への対応も進めています。
特に、実害発生リスクの高いECDSAに対する量子耐性を優先し、SHA-256については衝突検知後に速やかな移行を行う「寛容型量子耐性設計」を採用しています。
これは、理論上の完全性よりも、現実運用における安全性・持続性・移行可能性を重視した設計思想です。
FromHDDtoSSD は、
- ドライブ検査
- データ復旧
- 分散型基盤
- 長期安定運用
- AI推論型解析
- 量子耐性
を統合し、次世代の分散型データ保全基盤を目指します。
本ホワイトペーパーでは、その設計思想、技術構成、および実運用に基づくアーキテクチャについて解説します。
第一章 なぜ、データの最小単位「セクタ」を走査するだけでは、検査も復旧も成り立たないのか

ストレージ検査ソフトウェアの多くは、「セクタ」を基準として構築されています。
セクタとは、HDDやSSDにおけるデータ記録の最小単位であり、一般的には512Byteまたは4KB単位で管理されています。
従来の検査ソフトウェアは、このセクタを順番に読み取り、
- 読み取り可能
- 読み取り不能
- 応答速度
- CRCエラー
- 不良セクタ
などを判定することで、ドライブ状態を評価していました。
しかし、実際の故障現場では、それだけでは不十分です。
なぜなら、「壊れかけたドライブ」は、単純な正常・異常の二択では動作しないためです。
例えば、以下のような現象が発生します。
- 一度は読めたセクタが、次回は読めない
- 温度変化によって読み取り結果が変化する
- 数十回目の再試行で突然読める
- 周辺セクタへのアクセスで応答状態が変化する
- 一部だけ極端に応答速度が低下する
- 読み取り順序によって成功率が変化する
これは、単なる「不良セクタ検査」ではありません。
むしろ、
「壊れかけた記録媒体との対話」
に近いものです。
特に近年の大容量化では、この問題がさらに深刻化しています。
HDDやSSDの記録密度向上により、わずかな状態変化が大量データへ影響するようになりました。
さらにSSDでは、
- ウェアレベリング
- 内部ガベージコレクション
- ECC補正
- キャッシュ制御
- ファームウェア側の自動退避
など、多数の内部処理が存在します。
そのため、表面的なセクタ走査だけでは、実際の状態を正確に把握できません。
また、従来型ソフトウェアの多くは、
「正常ドライブ」
を前提として設計されています。
しかし実際のデータ復旧では、
- 異音が発生している
- 一部だけ応答する
- 長時間アクセスで停止する
- 特定位置で固まる
- 通電回数によって状態が変わる
など、「壊れかけ」の状態こそが主戦場となります。
このような状況では、
単純な全走査は、むしろ状態悪化を引き起こす場合があります。
例えば、
- 不必要な全域アクセス
- 長時間連続負荷
- キャッシュ暴走
- 温度上昇
- 劣化領域への再アクセス
によって、復旧可能だった領域が完全破損へ進行することもあります。
そのため、FromHDDtoSSD では、
単純なセクタ走査ではなく、
- 応答傾向解析
- アクセス順序最適化
- 推論型再試行
- 状態変化観測
- 部分整合性解析
- 分散型履歴共有
などを統合した設計を採用しています。
重要なのは、
「壊れているか」
ではありません。
「どのように壊れ始めているか」
です。
FromHDDtoSSD は、単なる検査ソフトウェアではなく、
壊れかけた記録媒体の挙動を解析し、
限界状態から可能な限りデータを救出するための基盤として設計されています。
第二章 セクタを読むだけでは終わらない ――FromHDDtoSSD の多層型ドライブ検査
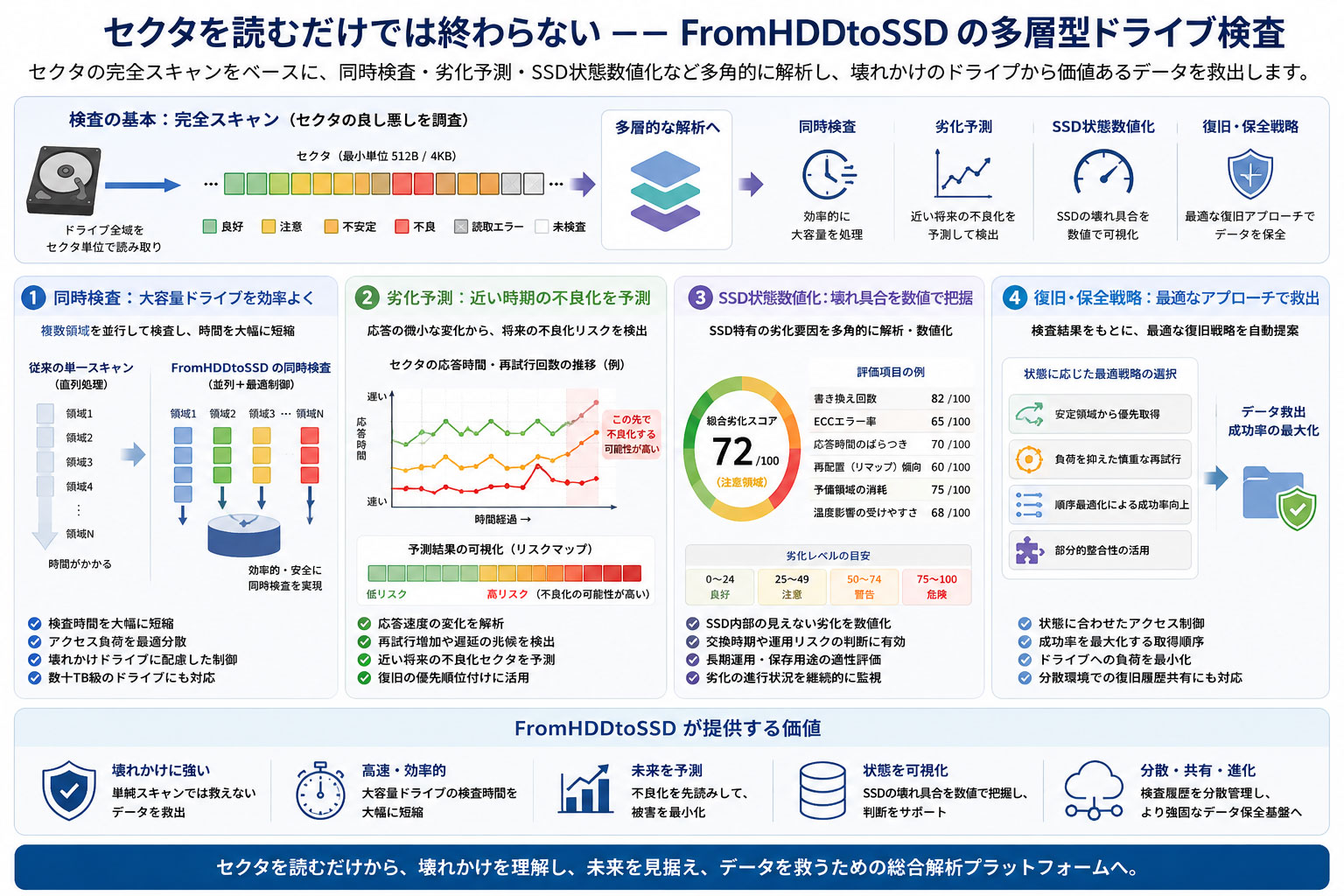
ストレージ検査における基本は、「セクタを正確に読むこと」です。
しかし、近年のHDDおよびSSDは大容量化・高密度化が進み、単純な全域走査だけでは、現実的な検査時間・故障予測・状態把握に対応できなくなっています。
FromHDDtoSSD では、従来の完全スキャンを基盤としながら、その上に複数の解析層を統合しています。
単なる「読める・読めない」の判定ではなく、
- 劣化傾向
- 応答変動
- 将来的な不良化予測
- SSD内部状態
- ドライブ負荷状況
まで含めて、多角的に解析します。
第三章 完全スキャンベースの設計

FromHDDtoSSD の検査基盤は、セクタ単位の完全スキャンを土台としています。
これは、
- 不良セクタ
- 応答遅延
- 読み取り不安定領域
- ECC補正発生傾向
- 部分的な応答崩壊
などを、物理層に近い形で観測するためです。
特に「壊れかけ」の状態では、ファイルシステムレベルだけでは検出できない異常が数多く存在します。
そのため、本プロジェクトでは、まずセクタレベルの全体把握を重視しています。
第四章 同時検査による大容量ドライブ対応

近年では、数TB〜数十TB級のストレージも一般化しています。
従来型の単純直列スキャンでは、検査時間が極端に長期化し、現実運用に支障をきたします。
FromHDDtoSSD では、複数領域を効率よく制御しながら解析する「同時検査」を導入しています。
これにより、
- 検査時間の短縮
- アクセス待機時間の削減
- 大容量ドライブ対応
- 負荷分散
- 劣化進行前の迅速な把握
を実現しています。
ただし、単純な並列化ではありません。
壊れかけドライブでは、アクセス順序そのものが状態悪化へ直結する場合があります。
そのため、本システムでは、ドライブ状態を観測しながら、アクセス制御そのものを最適化しています。
第五章 将来的な不良化予測

ストレージ障害は、突然発生するとは限りません。
実際には、
- 応答速度の微小変化
- 特定領域だけの遅延
- 再試行頻度の増加
- ECC補正傾向
- 温度依存変化
など、前兆となる挙動が存在します。
FromHDDtoSSD では、これらの状態変化を解析し、
「近い時期に不良化する可能性が高い領域」
を予測型に検出します。
これは単なる現在状態の観測ではありません。
「壊れ始めている兆候」
そのものを検出する試みです。
第六章 SSDの劣化状態の数値化
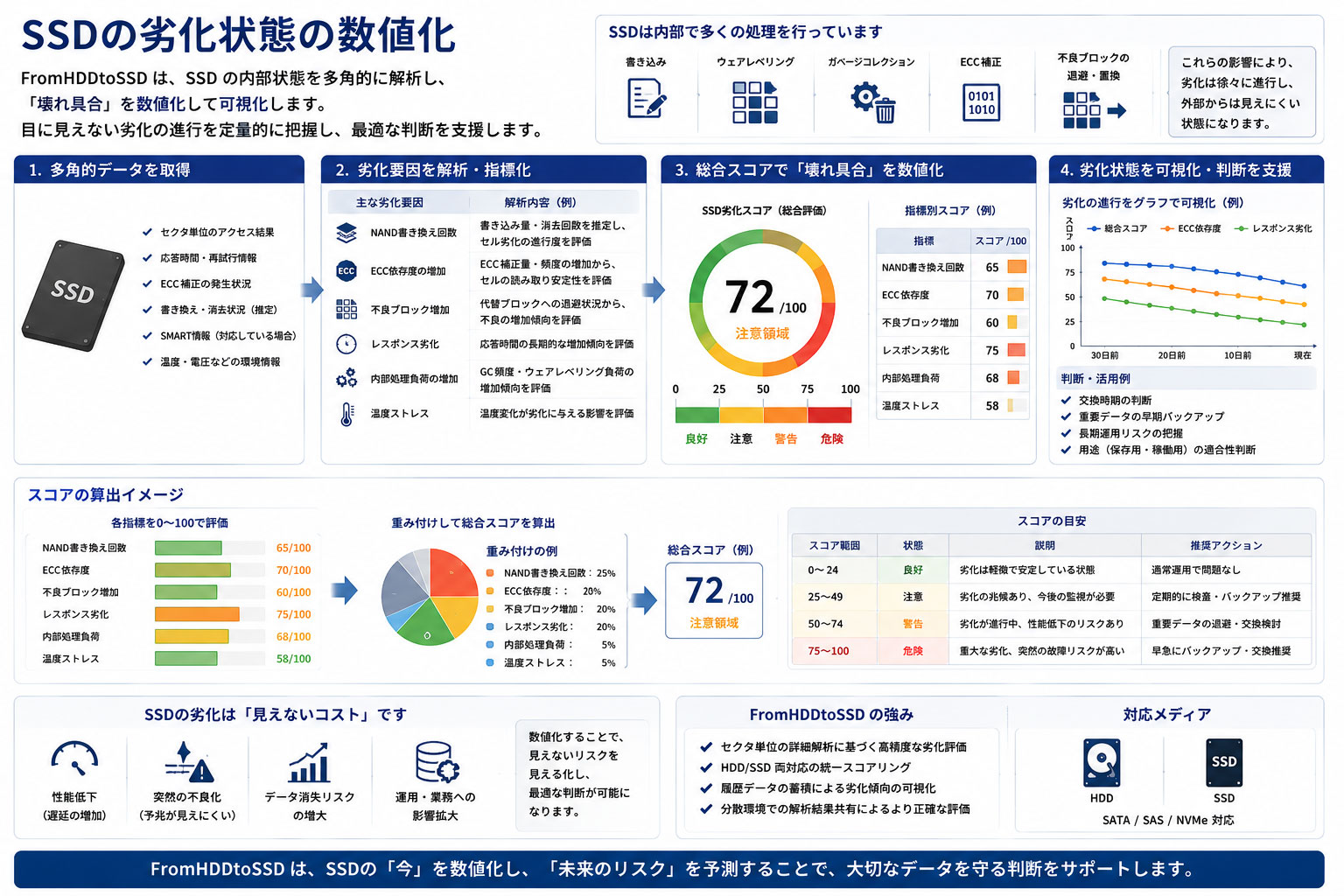
SSDでは、従来HDDとは異なる問題が存在します。
特に、
- NAND書き換え回数
- セル劣化
- ECC依存増加
- 予備領域消耗
- 内部退避増加
などは、外部から見えにくい問題です。
FromHDDtoSSD では、応答傾向・状態変動・アクセス結果などを解析することで、
SSDの「壊れ具合」
を可能な限り数値化し、可視化します。
これにより、
- 交換時期判断
- 長期運用リスク
- 劣化進行傾向
- 保存用途適性
などを把握しやすくしています。
第七章 単なるスキャンソフトではなく、状態解析基盤へ

本プロジェクトは、単純なセクタ検査ソフトウェアではありません。
重要なのは、
「今読めるか」
だけではなく、
「今後どう壊れていく可能性があるか」
です。
FromHDDtoSSD は、セクタレベルの完全スキャンを基盤としながら、
- 推論型解析
- 状態予測
- 劣化可視化
- アクセス最適化
- 分散型履歴管理
を統合することで、次世代のデータ保全基盤を目指しています。
第八章 AI完全自動データ復旧システムと、従来型マニュアル復旧操作の統合
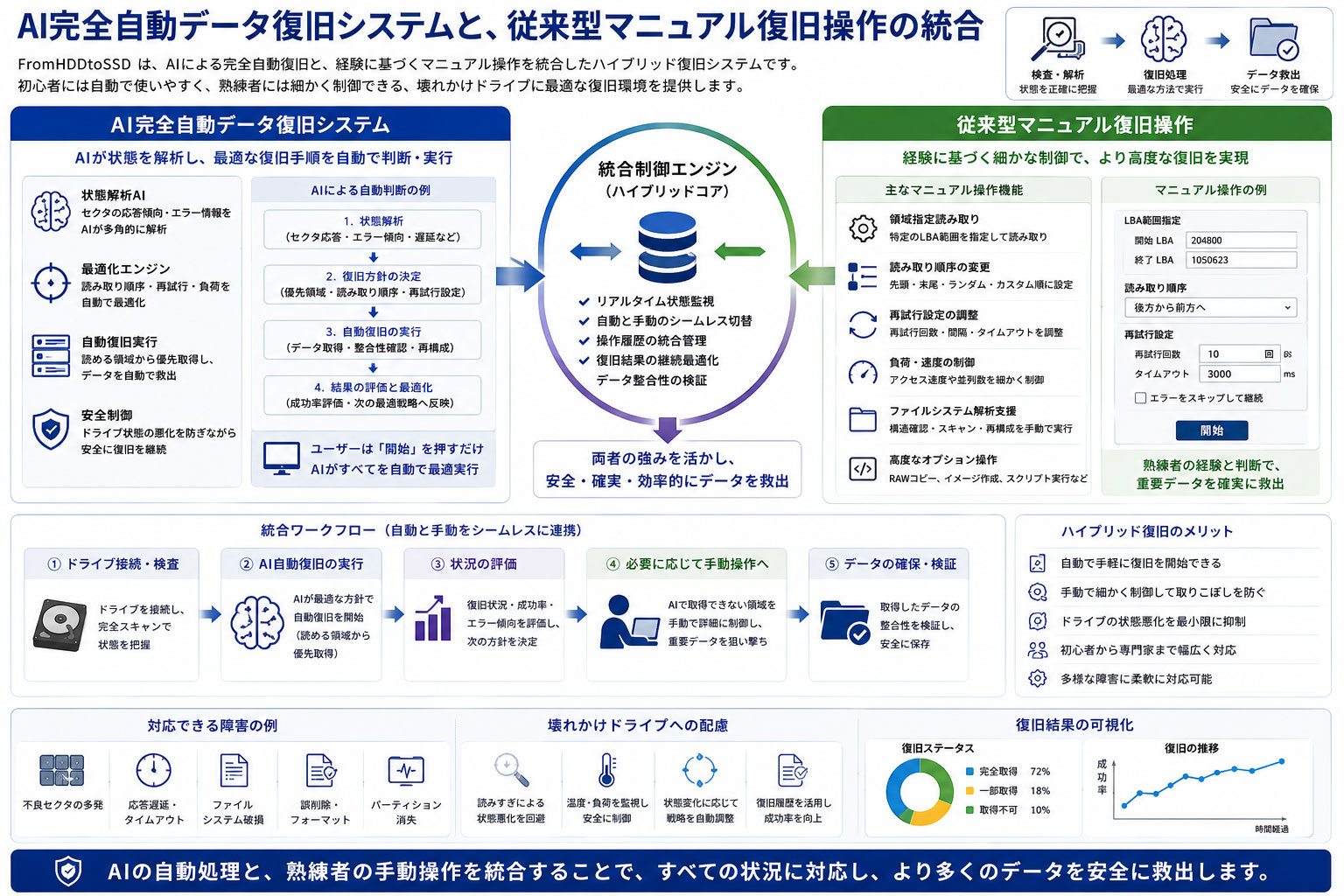
FromHDDtoSSD は、ドライブ検査だけでなく、データ復旧そのものを支援するための機能を備えています。
本章で扱う中心は、
「AIによる完全自動データ復旧」
と、
「従来のマニュアル操作による復旧」
の両立です。
データ復旧の現場では、すべてを自動化すればよいわけではありません。
壊れかけたドライブは、状態が一定ではなく、読み取り順序、再試行回数、負荷、温度、応答遅延などによって、復旧結果が変化します。
そのため、FromHDDtoSSD では、AIによる自動判断と、人間による細かな制御の両方を実装しています。
AI完全自動データ復旧システム
AI完全自動データ復旧システムでは、検査結果や応答傾向をもとに、復旧に必要な処理を自動で判断します。
具体的には、
- 読み取り可能領域の優先取得
- 応答が不安定な領域の後回し
- 再試行タイミングの最適化
- ファイル構造の推定
- 部分的な整合性の確認
- 復旧可能性の高い領域の優先処理
などを行います。
これにより、利用者は複雑な復旧手順を意識することなく、ドライブ状態に応じた復旧処理を実行できます。
マニュアル復旧操作
一方で、FromHDDtoSSD は従来型のマニュアル復旧操作も重視しています。
データ復旧では、経験に基づく判断が必要になる場面があります。
たとえば、
- 特定領域だけを先に読み出す
- 再試行回数を手動で調整する
- 読み取り順序を変更する
- 負荷を抑えながら少しずつ取得する
- ファイルシステム構造を確認しながら復旧する
- 重要ファイルを優先して救出する
といった操作です。
完全自動では拾いきれない状況に対して、熟練者が介入できる余地を残しています。
自動化と手動操作の両立
FromHDDtoSSD の特徴は、AI自動復旧とマニュアル復旧を対立させない点にあります。
AIは、膨大な状態情報を解析し、復旧方針を提案・実行します。
一方で、人間は、目的や重要度に応じて復旧対象を選び、細かな判断を加えることができます。
つまり、本システムは、
「初心者には自動で扱いやすく」
「熟練者には細かく制御できる」
復旧環境を提供します。
第九章 壊れかけドライブへの配慮
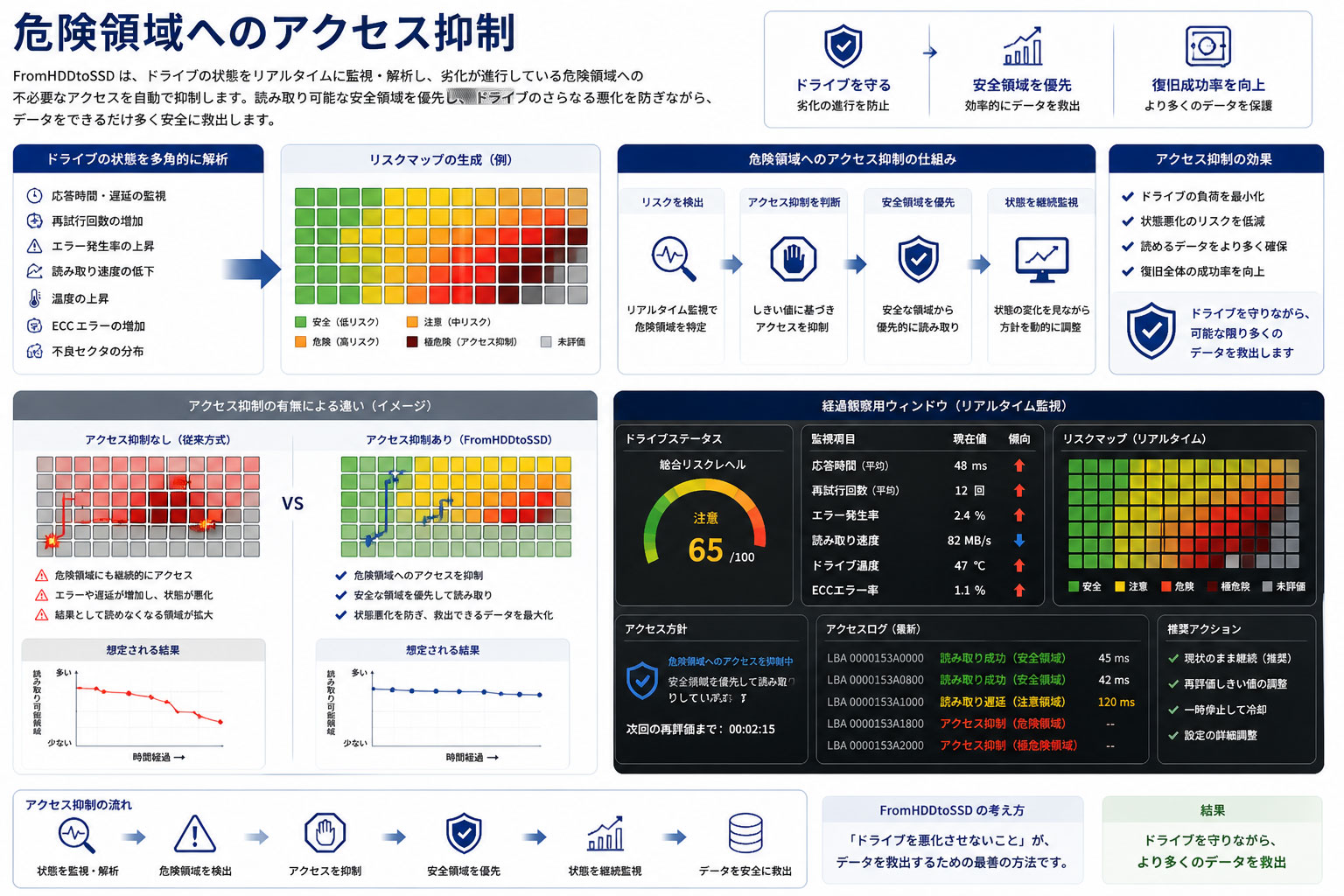
特に重要なのは、復旧対象が正常なドライブではなく、壊れかけたドライブであるという点です。
壊れかけたドライブに対して、不必要な全域アクセスや過剰な再試行を行うと、状態悪化を招く場合があります。
そのため、FromHDDtoSSD では、
- 読める領域から優先取得
- 危険領域へのアクセス抑制
- 状態変化に応じた再試行
- 負荷を抑えた復旧処理
- 復旧履歴に基づく判断
を重視しています。
第十章 データ復旧を、より安全で扱いやすいものへ
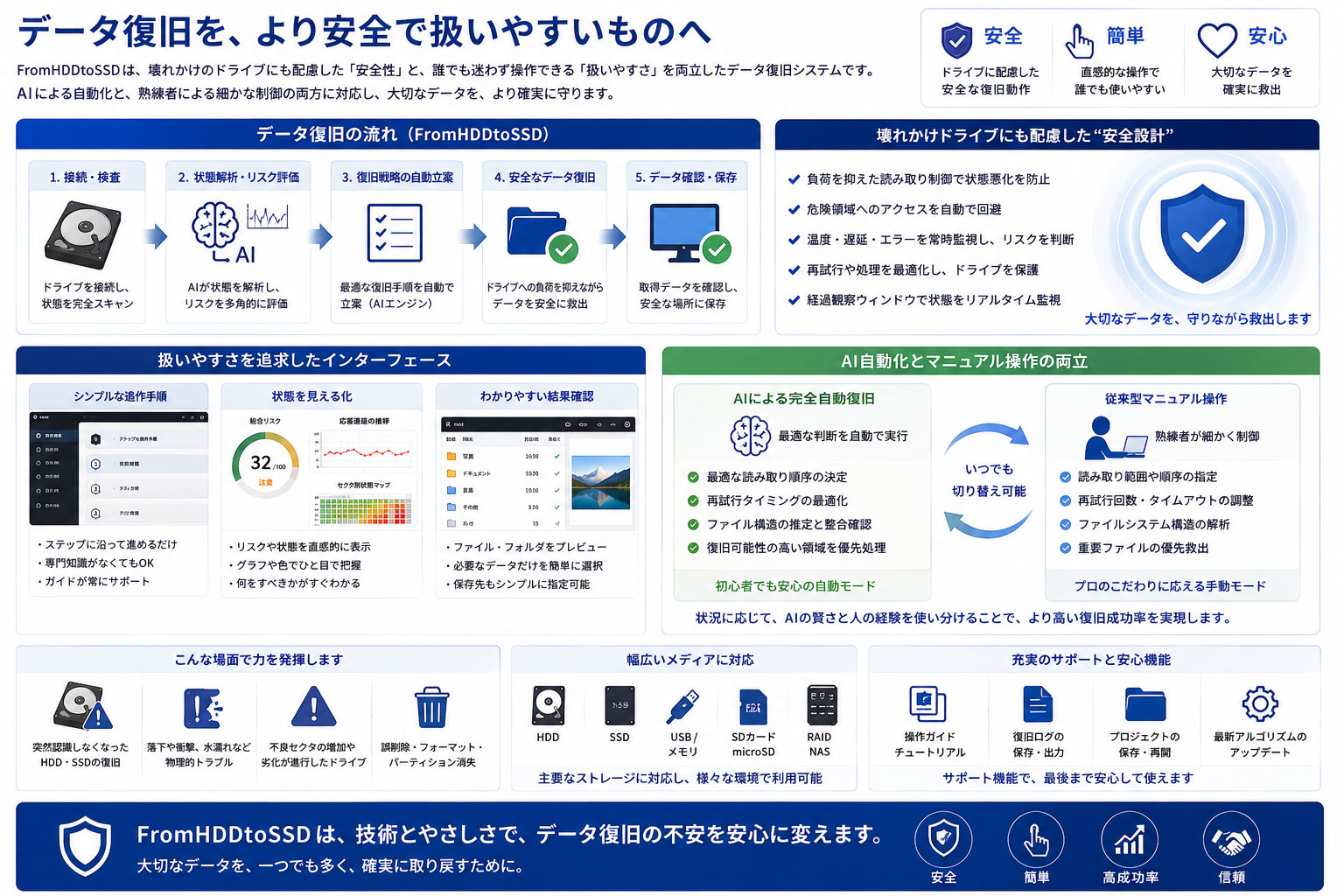
FromHDDtoSSD は、単なる自動復旧ツールではありません。
AIによる判断、マニュアル操作による精密制御、そして壊れかけドライブへの配慮を統合した、実用的なデータ復旧システムです。
自動化によって復旧の入口を広げ、手動操作によって専門的な復旧にも対応する。
それが、FromHDDtoSSD のデータ復旧設計です。
第十一章 SORA L1との連携 ブロックチェーンによる分散型システムの構築
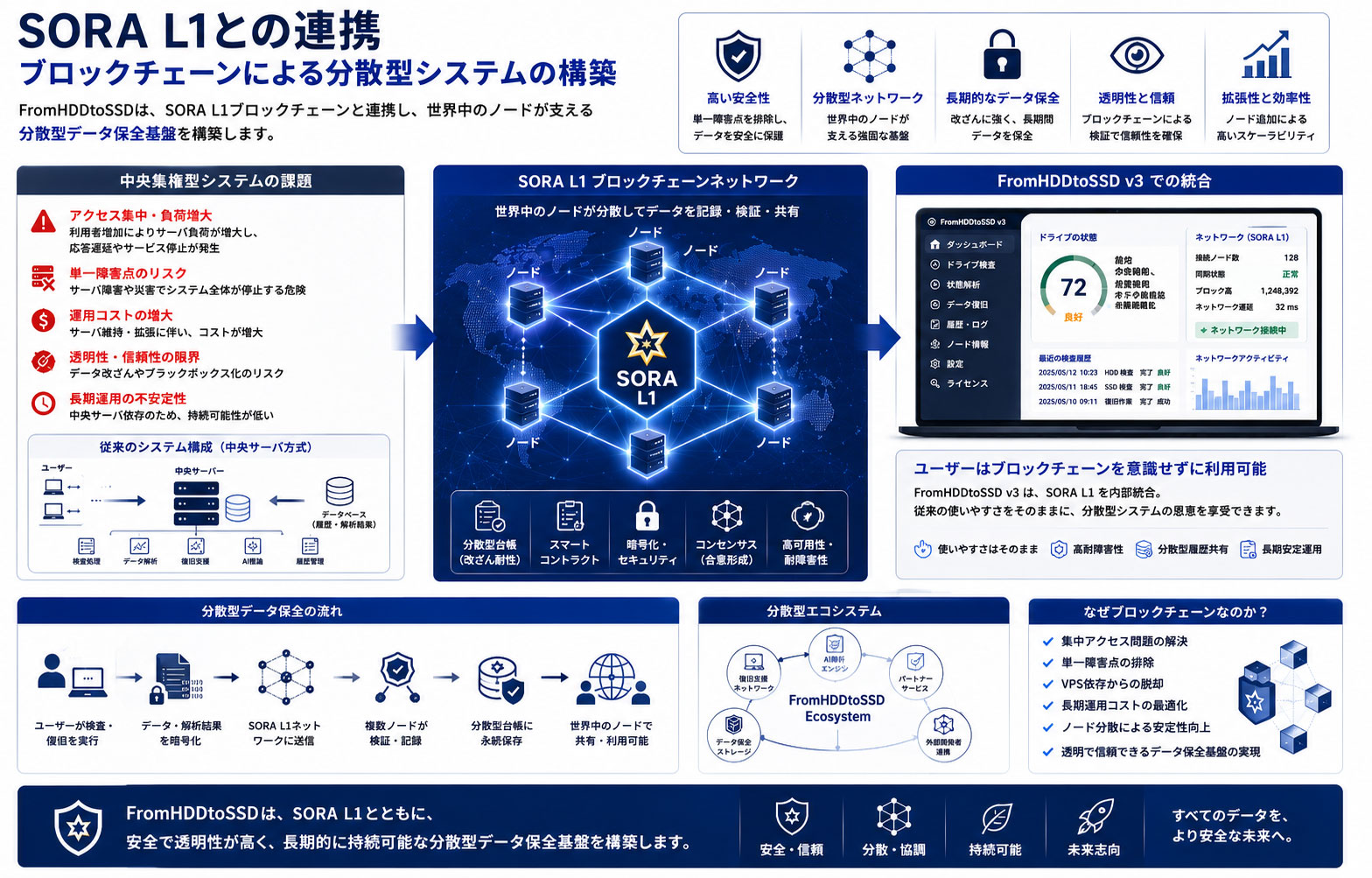
FromHDDtoSSD は、単体のドライブ検査・データ復旧ソフトウェアとして始まりました。
初期のクラウド型システムでは、
- 高度な解析
- 履歴共有
- 復旧支援
- AI推論処理
などを中央サーバ側で実行していました。
しかし、利用者増加とともに、中央集権型システム特有の課題が顕在化しました。
第十二章 中央集権型システムの限界

クラウド型システムでは、利用者が増加すると、アクセス集中が発生します。
特にドライブ検査やデータ復旧は、
- 大量ログ
- セクタ情報
- 応答履歴
- 劣化解析データ
- 推論用データ
などを扱うため、一般的なWebサービスと比較して負荷が非常に高くなります。
その結果、
- サーバ負荷増大
- 応答遅延
- 集中障害
- 運用コスト増加
- VPS依存
- 単一障害点
などの問題が発生しました。
さらに、中央サーバ依存型では、
「サーバが停止すると利用できなくなる」
という根本的な問題があります。
データ保全を目的とするシステムにおいて、単一障害点の存在は大きなリスクとなります。
分散型アーキテクチャへの移行
これらの問題を解決するため、本プロジェクトでは、分散型ブロックチェーン基盤「SORA L1」を導入しました。
SORA L1 は、単なる暗号通貨ネットワークではありません。
FromHDDtoSSD に必要な、
- 分散型履歴管理
- ノード共有
- 長期安定運用
- 非中央集権型検証
- 高耐障害性
を実現するための基盤として設計されています。
なぜブロックチェーンだったのか
本プロジェクトにおけるブロックチェーン導入の理由は、
「Web3化」
そのものではありません。
目的は極めて実務的です。
- 集中アクセス問題の回避
- VPS依存からの脱却
- 長期運用コスト最適化
- ノード分散による安定化
- 単一障害点の排除
これらを実現するために、分散型アーキテクチャが必要でした。
つまり、
「ブロックチェーンを使いたかった」
のではなく、
「分散化が必要だった」
というのが本質です。
第十三章 FromHDDtoSSD v3での統合

FromHDDtoSSD v3 では、この SORA L1 を内部統合しています。
そのため、一般利用者は、複雑なブロックチェーン操作を意識する必要はありません。
従来ソフトウェアと同様の感覚で利用しながら、
- 分散型履歴共有
- 高耐障害性
- ノード型安定運用
- 非中央集権型管理
などの恩恵を受けられます。
一方で、フルノードとして動作するため、初回同期など、ブロックチェーン特有の処理も存在します。
しかしこれは、
「中央サーバに依存しない」
ために必要な設計です。
第十四章 手数料設計
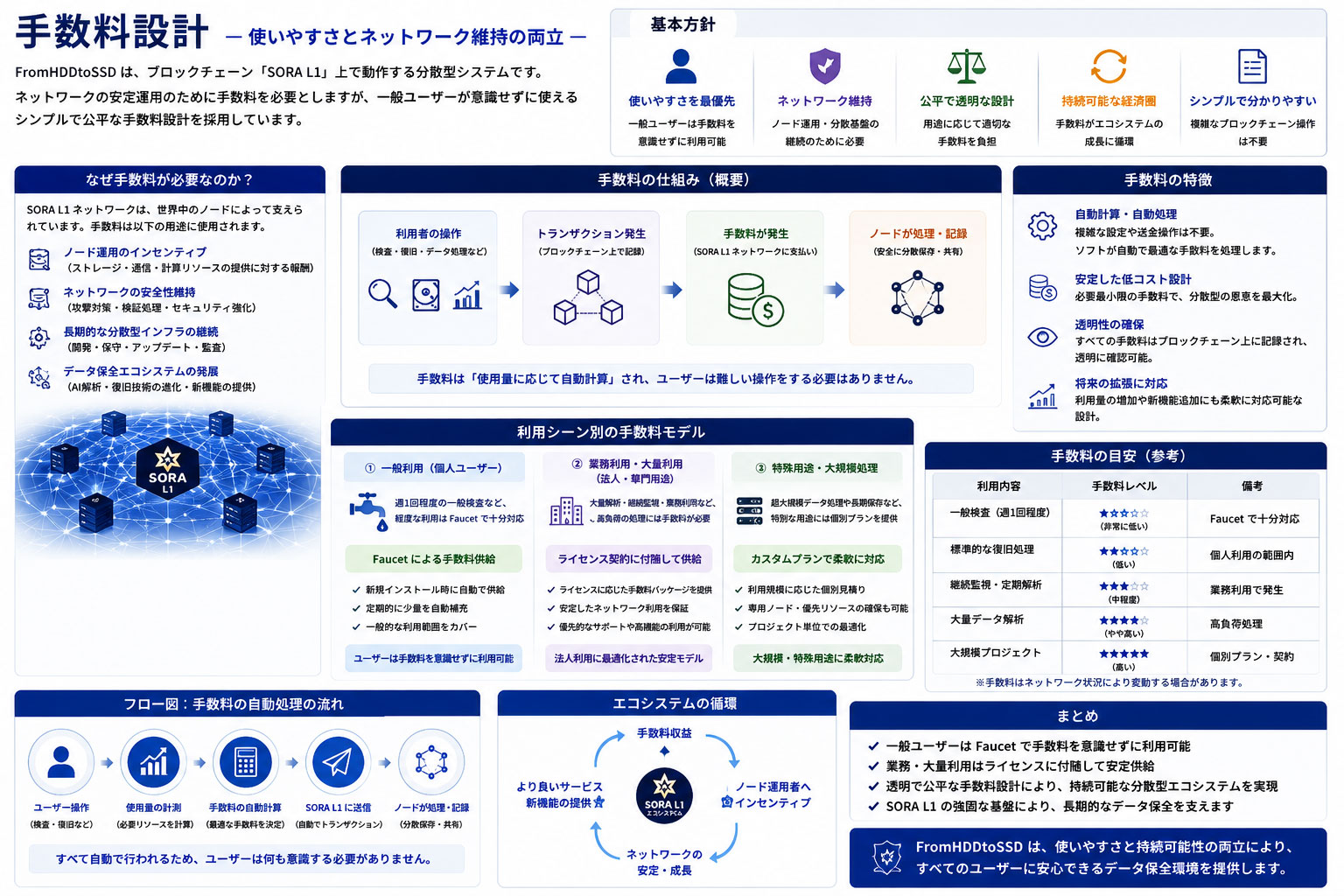
SORA L1 では、ネットワーク維持のために手数料システムを導入しています。
ただし、本プロジェクトでは、一般利用者がブロックチェーンを強く意識しなくても利用できる設計を重視しています。
通常用途(週1回程度の一般検査)については、Faucetによって十分な利用量を確保しています。
一方で、
- 業務利用
- 大量解析
- 継続監視
- 法人用途
については、ライセンス契約に付随する形で必要手数料を供給しています。
これにより、
- 個人利用の容易性
- 法人利用の安定性
- ネットワーク維持
- 分散型経済圏
を両立しています。
第十五章 分散型データ保全基盤へ
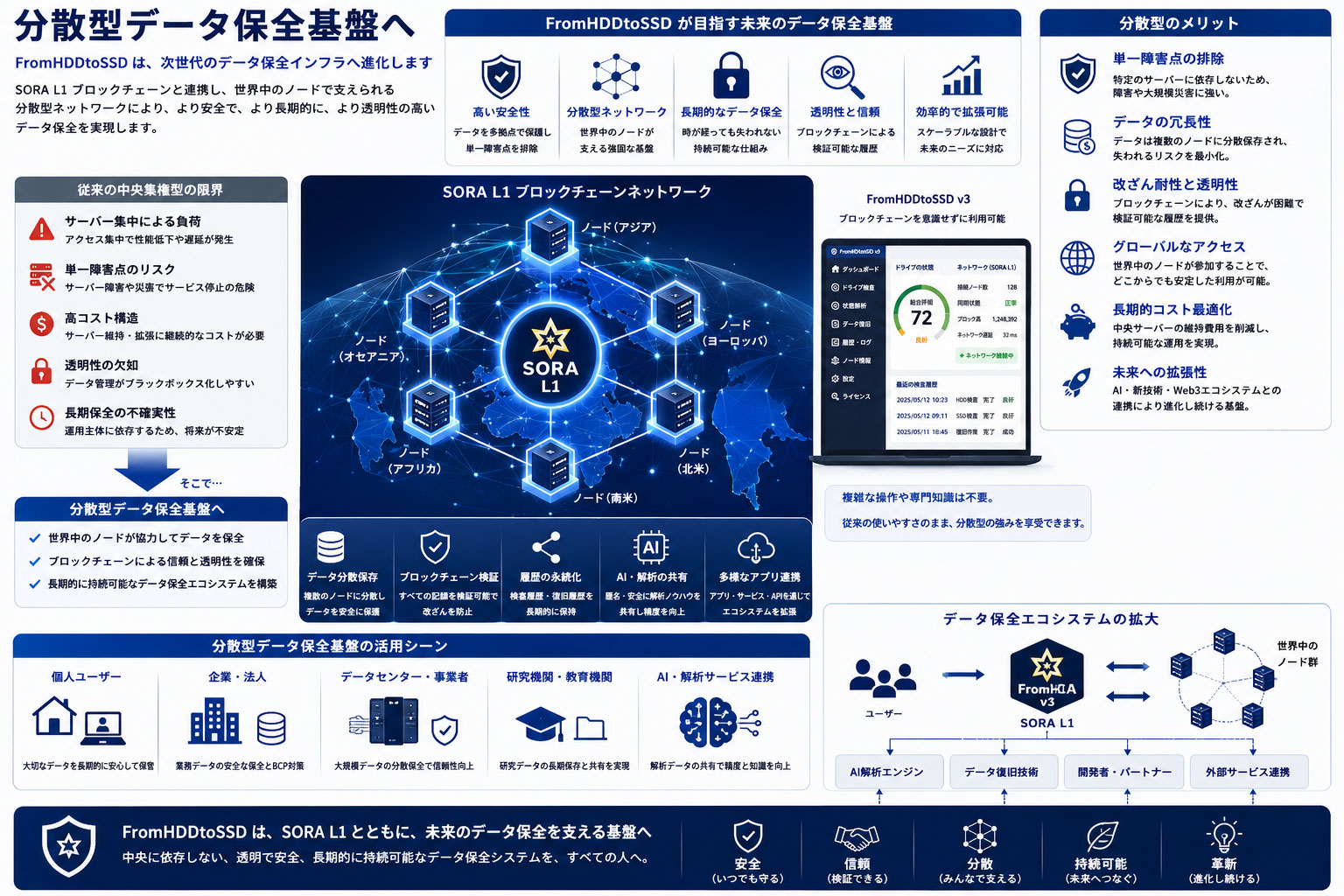
FromHDDtoSSD は、単なる復旧ソフトウェアではありません。
- ドライブ検査
- データ復旧
- 状態解析
- AI推論
- 分散型ネットワーク
- 長期保全
を統合した、次世代のデータ保全基盤を目指しています。
SORA L1 は、そのための「土台」として機能します。
中央サーバ依存ではなく、世界中のノードによって支えられる。
それが、本プロジェクトの目指す分散型データ保全システムです。