

ドライブを運用される場合、こまめにバックアップを取る事が前提ですが、常にバックアップを取る訳にもいきません。これには本当に大変な労力が発生いたします。なぜならば「冷蔵庫の貯蔵」と同じ理屈で、データが膨れ上がっていくという考察があります。このため、なぜかドライブの台数だけが増えていく、という現象にも納得です。
◇ ハードディスクに関する対処方法
1, 落下させた場合は、こちらの機能で念入りに検査をお願いいたします。
2, 温度について異常を検出いたしましたらバックアップを優先いたします。特に60℃を超えた場合は注意いたします。
3, 読み込みが極端に遅くなったと直感したときはサイズが小さい重要なファイルから、すぐにバックアップしてください。3.0TB以上の大容量ドライブでは一つのヘッドで担当するサイズが極端に大きくなっています。そのため、わずかなヘッド先端の損傷で、徐々に読み込めなくなる範囲が広がっていく性質があります。この影響は読み込みの速度に出てきて、直感で遅くなったと感じます。
◇ SSDに関する対処方法
1, 使用する容量を七割上限にして運用する。
※ かなり大切な対処法です。アルゴリズム的に、上限に近いところまで使用されると、予備のフラッシュが少なくなります。書き換え回数が多い偏ったフラッシュメモリの面積が大きくなって、寿命に影響します。比較的アクセスが多いセクタに不良セクタが出てしまう現象は、この要因が多くを占めております。
◇ バックアップ対策に関しまして:自動(差分)バックアップによる解決では不十分
ストレージ障害対策として行われる自動(差分)バックアップとなります。タスク処理にて空き時間に別のHDDへデータをコピーする作業、いわゆるバックアップです。
※ 万全と思われる「この仕組み」に落とし穴が潜んでおります。
>> 詳しくは 自動バックアップの危険性:失敗しても、通知の出ないケースがあります。
ドライブの異常を見つけやすくするには「読み書き」の一連動作を活用します。例えば、パーティションの分割バックアップを利用するだけで、異常検知の可能性を上げられます。
差分バックアップの設定をいたしますと、相手先は「書き込み」専用になる点が問題となります。なぜならば、異常が生じたときに、先に壊れるのが「読み込み」側である可能性が高いからです。つまり「読み込み」が壊れるよりも先に「書き込み」側が生き残ってしまいますと、読めないドライブへの書き込みになってしまいます。
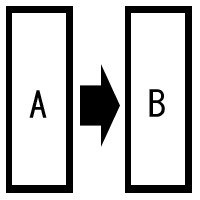 | 例1: 差分バックアップ (通常方法) AがメインのHDD、Bがバックアップ先のHDDと設定します。1日2回のペースでAからBへ差分のデータを送付しバックアップします。 |
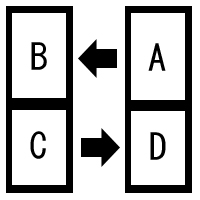 | 例2: 差分バックアップ (パーティション分割を利用し、交互に行う) 2台共、中央で区切りまして、2つのパーティションを作ります。AとCをメインパーティション、BとDをバックアップ先と設定します。1日2回のペースでAからB、CからDに差分のデータを送付しバックアップします。 |
例1では、先にBが消耗し、読み出しできない状態に陥ると、データ損失率に気が付けず、それが増していきます。なぜならば、書き込み系は動作するために、OSから故障を検知できないためです。そして、Bは読み出し操作を行わない為に、S.M.A.R.T.でも監視できません。この状態からAがヘッドクラッシュでも起こした場合、最悪の結果(全データ損失)となります。
しかしながら、例2では、AとCは別々のドライブゆえ、2台に程良い負荷が生じます。そして、それは「S.M.A.R.T.」によるエラー検出精度を上昇させます。それでも過信は禁物です。さらに読み出し系のエラーはシステムを停止させますので、1台のドライブに異常が生じたとき、それに気が付く確率が飛躍的に高まり、逆に安全です。
◇ RAIDの安全性に関しまして
ミラーリング(RAID-1)の場合、全てのドライブに対して「読み書き」が実施されます。ただし、誤削除・誤操作によるデータ紛失、ウイルスによる改ざん、劣化(全台破損)、論理障害などを防ぐことができません。それゆえに、ミラーのみの運用は、バックアップ以前にバックアップとしての機能すら果たしません。
RAIDにも、>> バックアップが必要です。
そして、ミラーリングに「バックアップ」を接続すると、最低でも3台を必要とするので非効率です。このような理由から「ミラーリング」は効率がとても悪くおすすめはできません。
