【ドライブ検査・データ復旧】RAIDはバックアップではございません
データ保護を目的とした仕組みとして紹介されることも多い、RAIDというシステム。
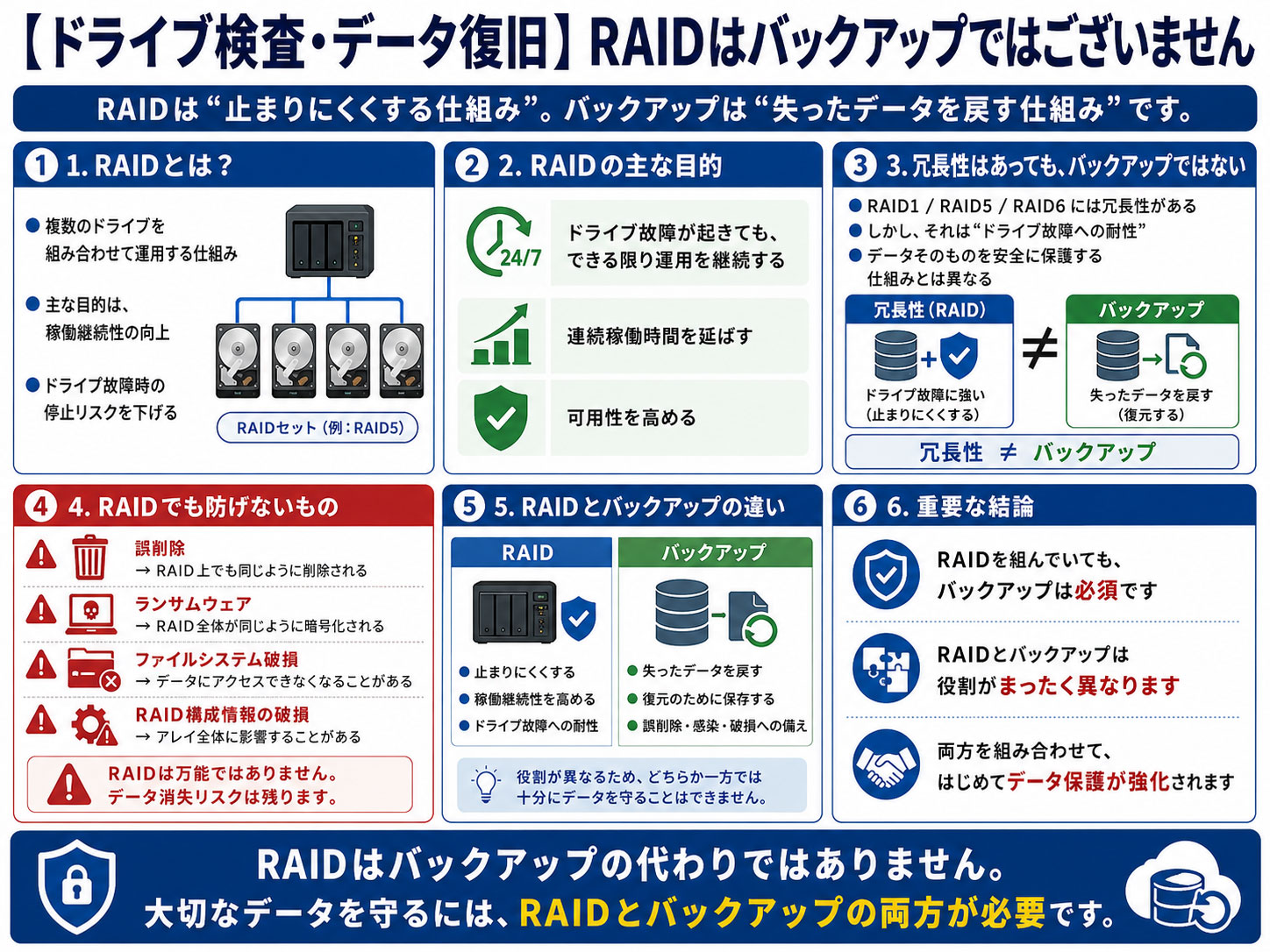
しかし、RAIDは本来、バックアップの代わりになるものではありません。
RAIDの主な目的は、ドライブ故障が発生した場合でも、システムの稼働をできる限り継続させることにあります。つまり、連続稼働時間を延ばし、停止リスクを下げるための仕組みです。
たしかに、RAID1やRAID5、RAID6などでは、ドライブ故障に対する冗長性があります。そのため、1台または複数台のドライブが故障しても、すぐにデータへアクセスできなくなるとは限りません。
しかし、それはあくまで「ドライブ故障への耐性」であり、データそのものを安全に保護する仕組みとは異なります。たとえば、誤ってファイルを削除した場合、RAID上のデータも同じように削除されます。
ランサムウェアに暗号化された場合も、RAID内のデータは同じように暗号化されます。ファイルシステムが破損した場合や、RAID構成情報が壊れた場合にも、データにアクセスできなくなることがあります。
つまり、RAIDは「止まりにくくする仕組み」であって、「失われたデータを戻す仕組み」ではありません。
この点を誤解してしまうと、RAIDを組んでいるから大丈夫だと思い込み、バックアップを取らないまま重要なデータを運用してしまうことがあります。
しかし、RAIDとバックアップは役割がまったく異なります。
RAIDは、稼働継続性を高めるための仕組み。バックアップは、データを失ったときに戻すための仕組みです。
この違いを理解しておくことが、データ保護において非常に重要です。
次回以降、このあたりをもう少し詳しく見ていきましょう。
自動バックアップには複数のHDDを接続して運用するRAID、自動的にバックアップを取れるように組み込んだシステム、同時にミラーを生成するミラーリングなどがございます。
これらは、シーケンシャルの高速化やデータの冗長性などを求めて組まれます。しかしながら、同時に脆弱性を抱え込む原因にもなっておりますので、それを説明いたします。
自動バックアップ
自動バックアップでは「徐々に」各ドライブが劣化する場合にデータを失います。失うかもしれません、ではなく、失いますので自動バックアップのみに頼るのは厳禁です。
数値の順:
空データ数, 実データ数, 読み込み不能セクタ数, 書き込み不能セクタ数, 読み書き不能セクタ数
同期前:
Disk1|90, 10, 00, 00, 00|
Disk2|100, 00, 00, 00, 00|
同期後:
Disk1|90, 10, 00, 00, 00|
Disk2|90, 10, 00, 00, 00|
各数値は全体を100として情報を保持している量を表します。
今回のDisk1は未使用が90、データ使用量が10、その他エラーのセクタはありません。新しいDisk2(新品なので未使用100)にバックアップした様子(同期)です。
自動バックアップが知らないうちにデータ損失
バックアップ先のドライブが故障するまで一切検査せずに使い続けるのは、とても危険です。
実は、この肝心な故障に気が付かない場合がとても多く、それこそ気が付いたときには、両方とも読めないという現象を沢山確認しております。
このようなデータ損失に至るまでの変化の流れ
数値の順:
空データ数, 実データ数, 読み込み不能セクタ数, 書き込み不能セクタ数, 読み書き不能セクタ数
新品の状態:
Disk1|55, 45, 00, 00, 00|
Disk2|100, 00, 00, 00, 00|
最初の同期(無事作動確認):
Disk1|55, 45, 00, 00, 00|
Disk2|55, 45, 00, 00, 00|
定期的に使用中、データ量55から80へ(無事作動確認):
Disk1|20, 80, 00, 00, 00|
Disk2|20, 80, 00, 00, 00|
障害の発生(無事作動確認):
Disk1|20, 80, 00, 00, 00|
Disk2|19, 80, 01, 00, 00|
障害の発生2(無事作動確認):
Disk1|20, 80, 00, 00, 00|
Disk2|19, 70, 11, 00, 00|損失10
障害の発生3(無事作動確認):
Disk1|18, 80, 02, 00, 00|
Disk2|15, 64, 21, 00, 00|損失16
障害の発生4(無事作動確認):
Disk1|18, 80, 02, 00, 00|
Disk2|10, 55, 30, 05, 00|損失25
障害の発生5(エラーで停止):
Disk1|18, 60, 02, 03, 17|損失20
Disk2|10, 55, 30, 05, 00|損失25
障害の発生6(5のエラーを無視、再度エラー、再起不能):
Disk1|00, 00, 00, 00, 100|損失80(ヘッドクラッシュ)
Disk2|10, 35, 50, 05, 00|損失45
Disk1(メイン側)が元気なのにDisk2(コピー先)が徐々に弱っていく
データを書き込んでから一定時間後に読み込み不能セクタに変化いたします。
同期の場合、ファイル名または更新日時に変化がない場合は書き込みしないためデータ損失が気付かれずに放置されてしまいます。頻繁に更新するファイルは書き込みの際にセクタが復活致しますし(エラーの場合もあり)、最終的に読み書き不能セクタになった場合はエラーで停止(書き込み不可)します。ほとんど更新しない(全く更新しない)保存用ファイルなどが影響を受けます。
更新頻度の低い例としてはデジタルカメラの画像などが犠牲となっております。
対策:更新頻度の低いファイルはできる限り別のメディアにも保存する。NASに接続されたバックアップ外付など最近は多いですね。
[重要] ミラーリングをバックアップとして利用してはいけません。
データ保護機能はありません。
ミラーリングはバックアップの代わりになりません。
まずウイルスやワームによる活動、人為的なミスによるデータ損失、論理的な障害については絶対に防ぐ事ができません。そしてドライブに対する見えない消耗が重なりシステムが停止したときには、すでに時遅しとなります。
接続されている全ドライブが破損していたという結果につながる恐れがあります。RAIDはあくまで稼働時間を延ばし決められた時間に修理を可能にする利点のみで、データ保護機能はありません。
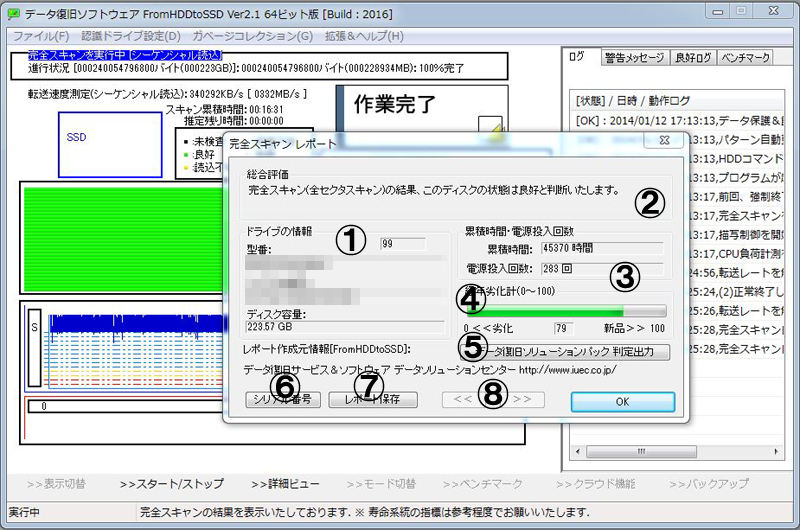
ドライブの検査: 弊社開発のFromHDDtoSSDで検査できます。
バックアップ先の劣化を定期的に検査し、徐々に弱っていくデータ損失を防ぐ事ができます。
検査はFromHDDtoSSDに備わる完全スキャン機能をご利用ください。