Web2のビッグデータあたりから、枠組みの概念の中にある技術に結び付ける開発方針に変わりました。
それまでは完全に独自で開発しており、効率は悪いのですが直接的な機能がよくできました。ところで枠組みの概念の中にある技術に結び付ける場合は、まずその枠組みの開発からになります。一見、効率が悪くみえてきますがその枠組みが稼働すると一気に開発効率が上がり、次々と各機能ができていきます。
ところが、万一その枠組み自体に問題が出ると、そこに組み上げてきた機能をすべて失うリスクが顕在しました。なお、Web2のビッグデータやクラウドなどでそのようなリスクはありません。マイナス面としてはサーバ代がかかる、それだけです。
そしてWeb3です。その顕在化したリスクにどう対処できるのかで、こちらに今後も重要な機能を実装してよいのだろうか、その判断を迫られている状況です。
そこで、Web3等の枠組みにとらわれず、蓄積してきたロジックとノウハウから、独自に構築する従来の方針に変更します。そしてWeb3に戻ることになったとき、そこで開発してきた機能を組み込み直す手間が発生いたしますが、使えなくなるリスクは取れません。
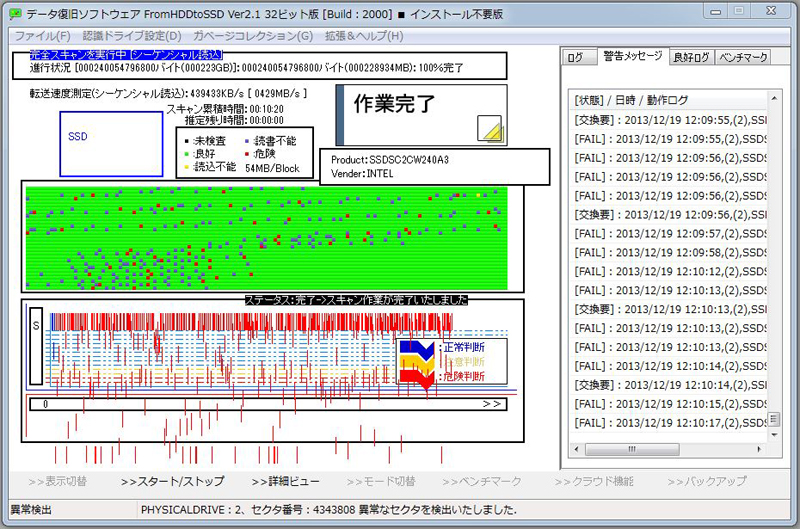
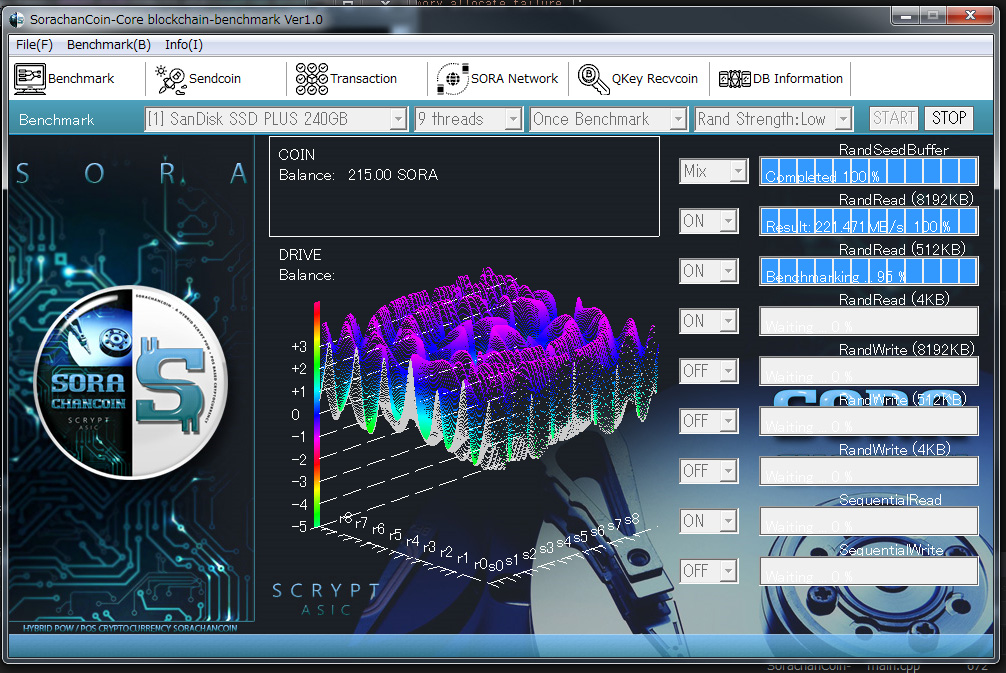
現状をまとめますと、v3 ブロックチェーン版に組み込んだ「統計スキャン」はv2への移植が可能ですが、「暗号のメモ帳」はブロックチェーンに完全依存した機能となるため移植は不可となります。もし自律した自動復旧機能を組み込んでいた場合、これもブロックチェーンに完全依存するので移植は不可になります。枠組みにとらわれず個別の機能をリリースしていき、v3をメンテナンスしながらv2を継続。ブロックチェーンが信用回復したらv3再開。この流れで開発継続の見通しとなりました。